背景
因为我们现在使用的图数据库都有一个瓶颈就是不支持图数据库集群 在图数据库的使用上我们只可以使用单点 如果使用多点 那么就会有很多缓存不一致等问题 因为现在开源的图数据库d很多都是企业内部图数据库的阉割版 都是不支持图数据库层面的集群的 所以不可以做上线版本的 那么离线分析可以作为一个方向
离线数据
都是csv格式的文件 文件中每一行的格式都很单一 就是
userid,fileid
例如
311915299,10437872764
每一条数据意味着某个用户id读了某个文件id
而且这些数据所有都是fileid具有约束条件pv<6的 这次离线分析的思想很简单就是: 物以类聚 人以群分 想通过以fileid为中心形成很多子图 而且pv<6使得这些文件都不是属于烂大街的文件和具有普适性的 比如文档教程之类 过于烂大街的文件形成的子图对于我们来说没有什么价值 因为它们无法为我们的用户画像带来帮助 那么这些文件的属性大概率可以表明这些子图中用户的身份 比如以简历为中心的子图中的用户大概率是应届毕业生之类的 思路是很简单的
schema和graph
所有的代码都在subgraph
构建子图部分如下:
构建图的思路很简单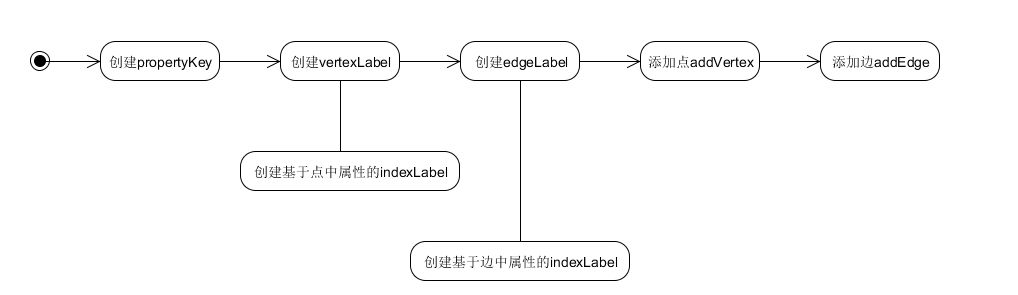
在hugegraph里面上面的创建其实是分为两部分的
- schema
- graph
对应上面图中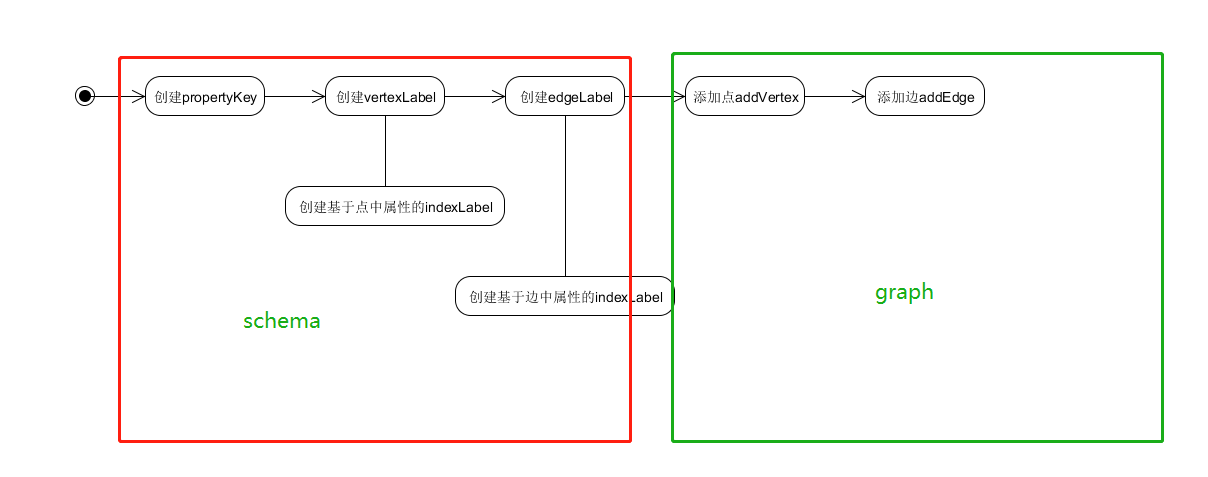
分别对应项目中如下两部分
这里有必要说一下我代码里面一些单元测试 单元测试在我的代码里面很重要 在这里我基本是写一个函数就对应写一个单元测试 这样你看我的代码 看我的单元测试就知道这些函数是怎样使用的了 所以看我的代码 看我的单元测试是关键
代码中schema文件夹下schema.go就是用来构建schema中propertyKey vertexLabel edgeLabel中的函数 在schema_test.go中可以看到这些对应函数的使用方法 同时也有部分注释
代码中schema文件夹跟上面类似
读取csv数据构造图
入口在如下main函数
ConstructGraph函数每一次读取一个csv文件 迭代处理每一行 对于每一行
userid, fileid
先生成一个user的点和一个file的点 以及生成一条从user指向file类型为connect的边 一直重复上述操作 直至数据被处理完
上述的操作有两点要注意的地方:
- 我是单线程同步构造图的 但是73哥csv耗时上并不是太长 可以接受
- 如果对构造图有耗时上的要求 那么推荐使用无gremlin的纯graph api(restful api)
查询子图

查询的函数和单元测试都写在上面的红色部分内 入口在下面的绿色部分内
查询就是使用gremlin api发送gremlin语句过去 这里真的是一句gremlin用到烂 主要用的一句gremlin就是
1 | const SubGraphGremlin = "sg = g.V().hasLabel('file').has('fileid','%s').repeat(bothE().subgraph('sg').otherV().simplePath()).until(bothE().count().is(0)).cap('sg').next();sg = sg.traversal();r=sg.V().choose(hasLabel('user'), count(), values('fileid'));r" |
我们在hugegraph上进行查询大多数情况都是在gremlin上做文章 对于gremlin的语法我们需要很注意 所以这里是说一下上面这段gremlin是什么意思
可以分为四部分
1.
sg = g.V().hasLabel('file').has('fileid','%s').repeat(bothE().subgraph('sg').otherV().simplePath()).until(bothE().count().is(0)).cap('sg').next();
g是一个全局Traversal(全局遍历器) 理论上使用这个全局遍历器awo我们可以首先定位到图里面的某个点或者某部分点 并且以这些点作为我们迭代查询的始点 要注意g其实是这个全局遍历器的别名 在代码里面使用gremlin api post发送gremlin语句的时候需要加上这个别名 否则无法识别g是什么 比如我在在子图的代码里是这样写的
详细解释如下
2.
sg = sg.traversal();
对上一个步骤获取的子图sg 获取这个子图的一个遍历器
3.
r=sg.V().choose(hasLabel('user'), count(), values('fileid'));
通过这个遍历器 通过choose语句 choose语句相当于if else逻辑 满足第一个参数条件 则执行第二个参数 否则执行第三个参数
所以上面的意思是如果子图里面的点是有user的label的话 那么返回这些点的数量(子图中用户数量) 否则(就是file的点) 返回浙西file的fileid属性 并且将上诉结果都放到一个r变量中
4.
r
返回查询结果