元素的比较
在java里面元素的对象的比较一般是通过实现comparable或者comparator这两个接口来实现的
比如下面一个类 实现了comparable接口 实现接口必须覆写compareTo这个方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31package basics.compare;
/*下面的Comparable<SearchResult>加上了泛型限定*/
public class SearchResult implements Comparable<SearchResult> {
int relativeRatio;
long count;
int recentOrders;
public SearchResult(int relativeRatio, long count) {
this.relativeRatio = relativeRatio;
this.count = count;
}
/*需要覆写compareTo方法*/
public int compareTo(SearchResult o) {
if (this.relativeRatio != o.relativeRatio) {
return this.relativeRatio > o.relativeRatio ? 1 : -1;
}
if (this.count != o.count) {
return this.count > o.count ? 1 : -1;
}
return 0;
}
public void setRecentOrders(int recentOrders) {
this.recentOrders =recentOrders;
}
}
但是comparable接口其实不如comparator好 因为当我们需求有改变的时候 如果使用前者 意味着需要修改已经提交的代码 如果我们使用后者 那么当与比较相关的需求改变的时候 我们只需要修改第三方比较器就可以了 下面就是一个后者的例子 注意comparator这个接口的实现必须覆写compare这个函数
1 | package basics.compare; |
上面我们也使用了泛型的知识 这个就不展开了
相等
上面我们介绍的是比较 主要说的是comparable跟comparator这两个接口 那么跟我们这里说的相等有什么区别呢
comparable跟comparator都是两个类的实例用来判断大小或者说按照一种规则对这些元素进行排序的 但是这里说的相等主要是判断两个对象是否相等 相等或者不想等就完事了 没有所谓的排序 这里的场景主要是在一些map或者set集合中用来判断两个对象是否是一个相同的对象 在去重方面发挥作用
下面我们主要说一下”相等”这个概念在TreeMap跟HashMap这两个常用的Map里面有什么不同
首先我们了解一下TreeMap跟ConcurrentHashMap和HashMap在使用上的一些不同:
- TreeMap的Key是有序的 可以支持范围查找 所以在一些需要排序的场景下很好用
- ConcurrentHashMap和HashMap在插入和删除方面上更高效 所以后面两者更常用
TreeMap的key排序去重并不是基于key元素覆写hashcode函数跟equal函数的 而是实现了接口comparable 覆写了compareTo函数
1 | class Key implements Comparable<Key> { |
那么HashMap是怎样实现元素的去重的呢
HashMap依靠hashCode函数跟equal函数来实现去重1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class NewKey {
public int hashCode() {
return 1;
}
public boolean equals(Object obj) {
return true;
}
}
/*下面的代码输出是1 因为:
*
* TreeMap依靠实现comparable接口 覆写compareTo函数来实现去重
* HashMap依靠hashCode函数跟equal函数来实现去重
*
* 所以下面的代码输出是1 HashMap把两个Key都当作是相同的了*/
public class HashMapUsage {
public static void main(String[] args) {
HashMap hashMap = new HashMap();
hashMap.put(new NewKey(), "value one");
hashMap.put(new NewKey(), "value two");
System.out.println(hashMap.size());
}
}
fast-fail和fast-save机制
fast-fail机制
fast-fail机制是一种对集合遍历操作时的错误检测机制 在遍历途中出现意料之外的修改时 通过uncheck异常暴力反馈出来
这种机制通常出现在多线程环境下 当前线程会维护一个计数比较器 即expectedModCount 记录修改的次数 在遍历之前 会把实时修改modCount赋值给expectedModCount如果两个数据不想等就会抛出异常
这里我之前看源代码就有发现 具体见ArrayList相关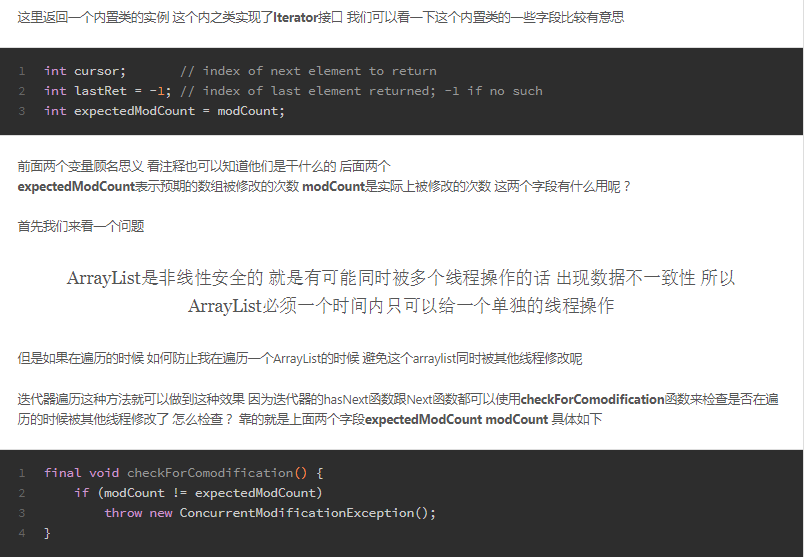
我们知道ArrayList就是fast-fail的 那么我们有哪些常见的是fast-save的呢 下面要介绍CopyOnWriteArrayList用来代替ArrayList 该容器会对内部的迭代器进行加锁操作
顺便我们这里介绍一下COW奶牛家族 就是copy on write的意思
它是并发的一种新思路 实行读写分离
- 写操作就复制一个新的集合 在新集合上添加或者删除 等到修改结束 将原集合的引用指向新的集合
- 读和遍历操作 不需要加锁 直接读
但是在使用cow的时候需要注意
- 尽量设置合理的初始容量 这跟ArrayList那些是一样的 因为扩容代价太大
- 使用批量添加或者修改 避免频繁复制整个集合 消耗内存
下面是一个简单例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27/*下面我们使用了COW家族的一员 就是copy on write机制
*
*
* 这个机制适合使用在读多写极少的高并发场景下
*
* 因为他的原理就是:实行读写分离 如果是写操作 则复制一个新集合 在新集合中添加和删除元素 待一切修改完成之后 再将原集合的引用指向新的集合 这样做的好处就是可以高并发地对COW进行读和遍历操作 而不需要加锁 因为当前集合不会添加任何元素
*
*
* 使用注意要点:
* 1. 尽量设置合理的容量初始值 因为会设置扩容的问题
* 2. 使用批量添加或删除的方法 因为每一次修改都是需要copy出一份新的集合出来的 如果分开修改 那么代价很大
*
*
* 有点和缺点:
* 优点:是线程安全的
* 缺点:不能读取到最新的数据*/
public class CopyOnWrite {
public static void main(String[] args) {
CopyOnWriteArrayList<Long> list = new CopyOnWriteArrayList<Long>();
long start = System.nanoTime();
for (int i = 0; i < 10; i++) {
list.add(System.nanoTime());
}
long end = System.nanoTime();
System.out.println("cost time " + (end - start));
}
}