cayley查询过程
cayley的查询过程相当复杂 下面是我个人的学习结果 仅仅是个人看法 无法保证绝对正确
构造态射数组
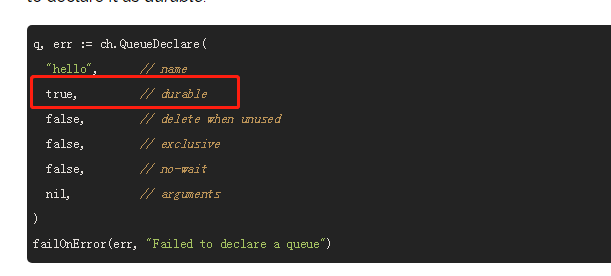
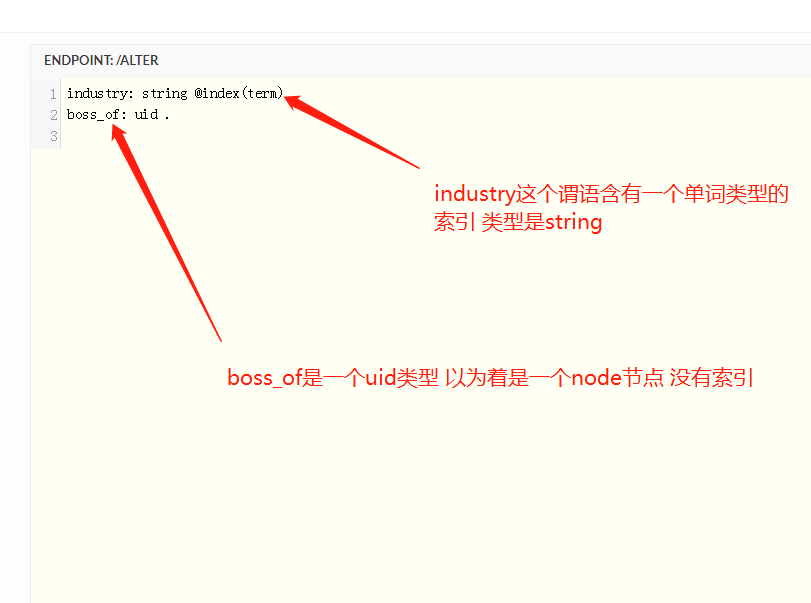
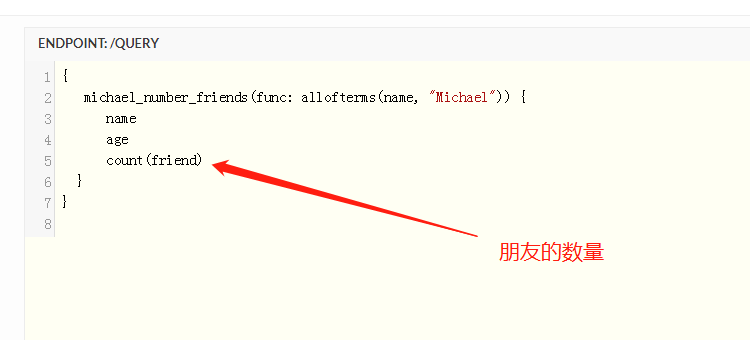
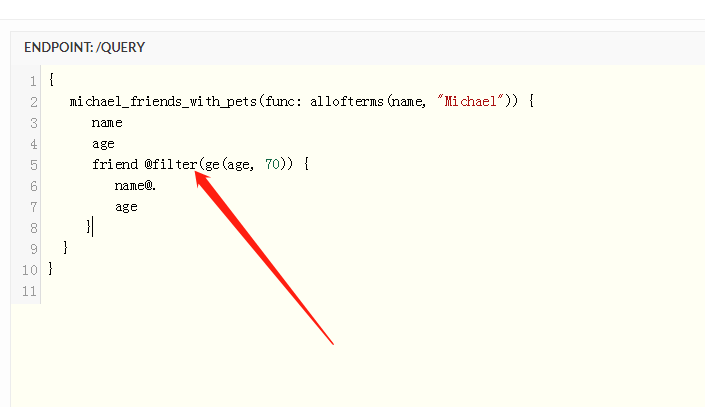
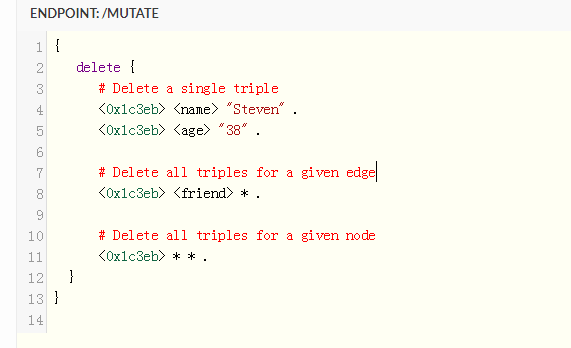
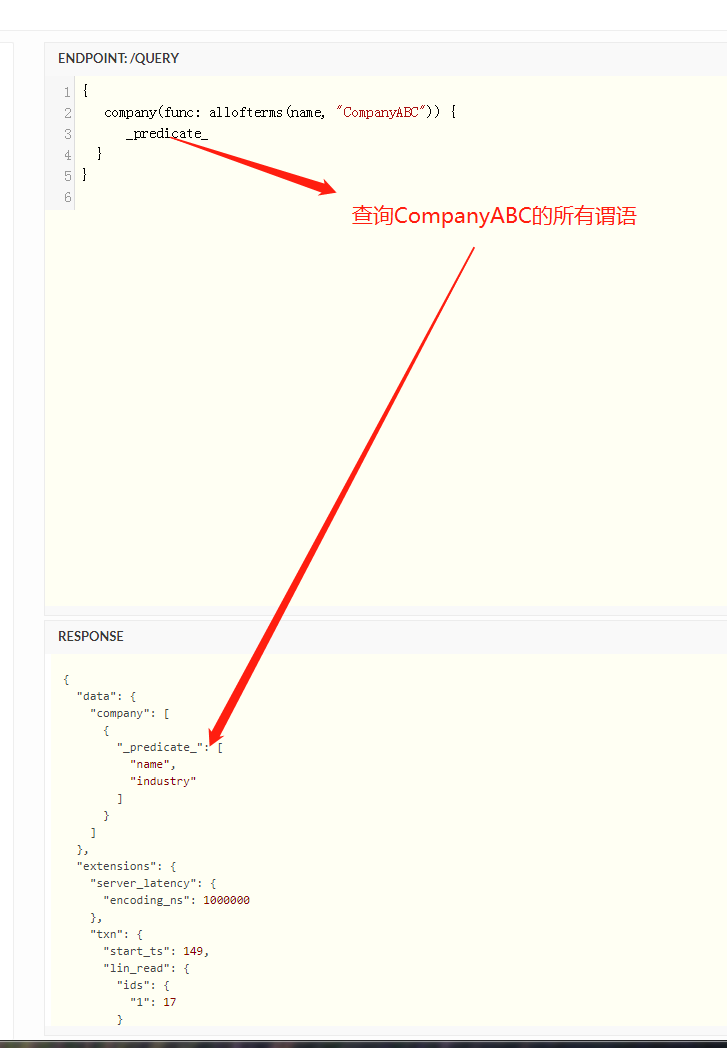
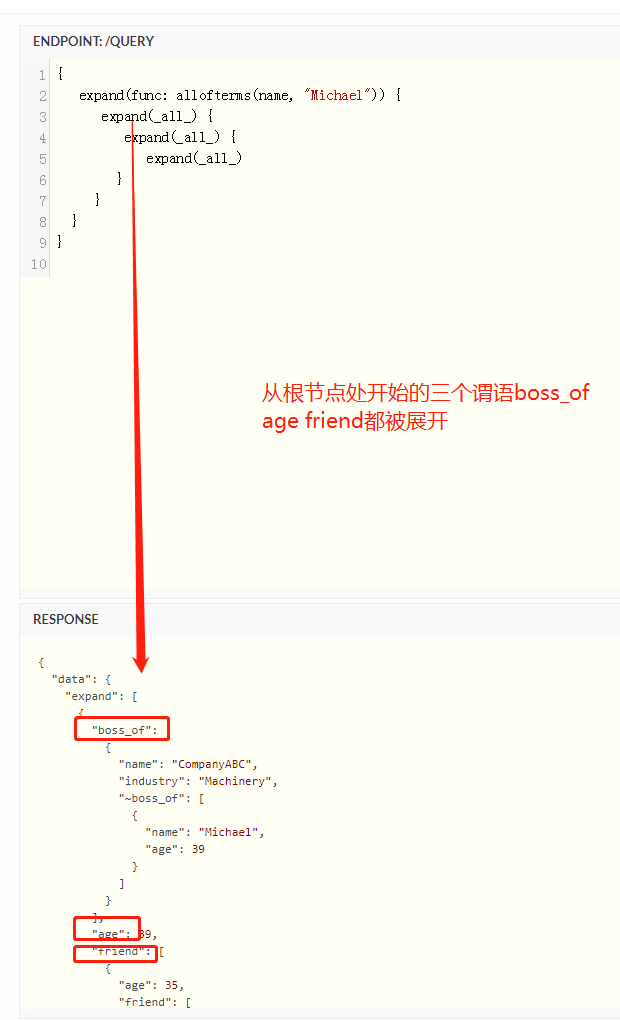
在cayley中的查询一般我们都是构造一个path结构体实例 例如查询从A出发 经过节点12 可以达到什么节点
p := cayley.StartPath(store, quad.String("A")).Out(quad.Int(12))
上面的语句实质上返回一个path实例 就是p 对于我们用来查询的结构path1
2
3
4
5type Path struct {
stack []morphism
qs graph.QuadStore // Optionally. A nil qs is equivalent to a morphism.
baseContext pathContext
}
上面有一个重要的字段
stack []morphism
morphism态射在范畴论中就是一个函数变换的抽象过程 cayley中的态射我们可以理解是我们每一个out int has等等指向下一个节点迭代的函数封装 我们每一个指向下一个的迭代(in out等)都转换为一个morphism态射 然后存在path中的stack态射数组
这个stack存储着表示我们查询的每一个划分(out in has等等)的态射
每一个态射在cayley中的定义1
2
3
4
5
6type morphism struct {
IsTag bool
Reversal func(*pathContext) (morphism, *pathContext)
Apply applyMorphism
tags []string
}
- 其中Reversal返回的态射是一个反向的态射(比如out的反向态射就是in) 这就是cayley实现无向图的原因 每个态射都包含一个它的反向态射
- Apply为执行这个态射的具体函数 这个函数返回值中得到的shape中就表示了执行态射后得到的节点
举一个简答的例子 也是上面那个例子
p := cayley.StartPath(store, quad.String("A")).Out(quad.Int(12))
上面这条查询语句在声明了一个path结构体的同时 也构造出我们上面所说的态射数组
下面的绿色大框即为我们的态射数组stack 两个蓝色框即为我们数组中的两个态射 都是morphism结构体 但是我们可以看红色框框 他们的apply这个函数是不一样的 一个是isMorphism 一个outMorphism
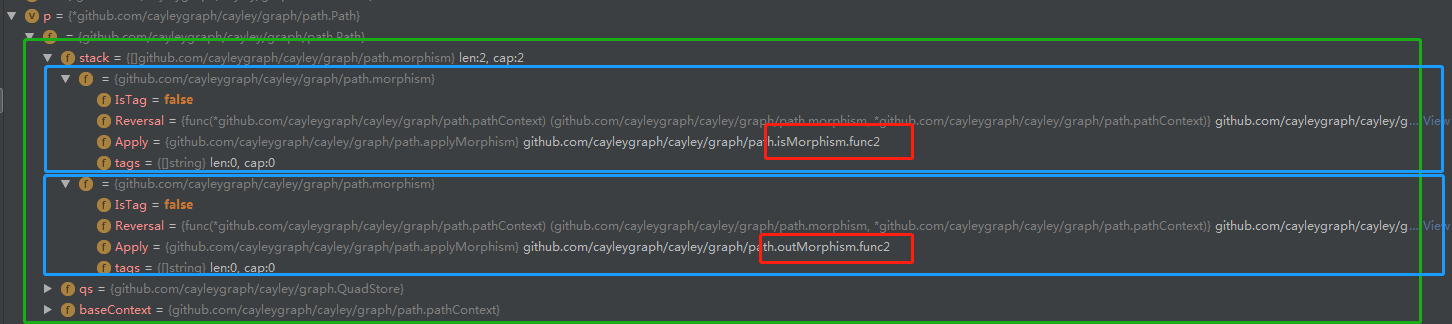
我们可以很容易理解为什么有outMorphism态射 但是不能理解为什么有isMorphism这个态射 其实isMorphism是初始化的态射
构造shape
shape顾名思义就是我们查询路径的一种表现形式 表示了我们使用path查询始末的一条抽象路径 如上面的查询抽象的一个shape就是
A -> 12 ->
shape在cayley中只是一个接口 但凡实现了这个接口中的方法的结构体都是shape 具体的形式非常多样和复杂 我们这里不做详细研究 shape接口定义如下1
2
3
4
5
6
7
8
9
10
11
12// Shape represent a query tree shape.
type Shape interface {
// BuildIterator constructs an iterator tree from a given shapes and binds it to QuadStore.
BuildIterator(qs graph.QuadStore) graph.Iterator
// Optimize runs an optimization pass over a query shape.
//
// It returns a bool that indicates if shape was replaced and should always return a copy of shape in this case.
// In case no optimizations were made, it returns the same unmodified shape.
//
// If Optimizer is specified, it will be used instead of default optimizations.
Optimize(r Optimizer) (Shape, bool)
}
一个具体的shape的例子 可见shape的具体类型和机构是很多样的 没必要具体研究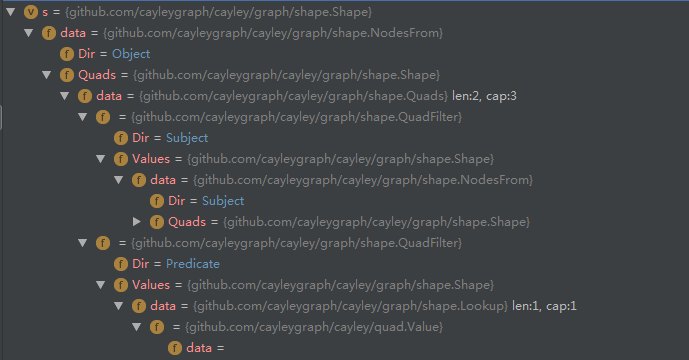
可以看到下面 随着态射一个一个被执行 我们的到的构造出来的shape也是变化的 每一次态射之后的到的shape都作为参数传入下一个被执行的态射函数 shape不断积累 不断拓张 最终形成我们需要的查询路径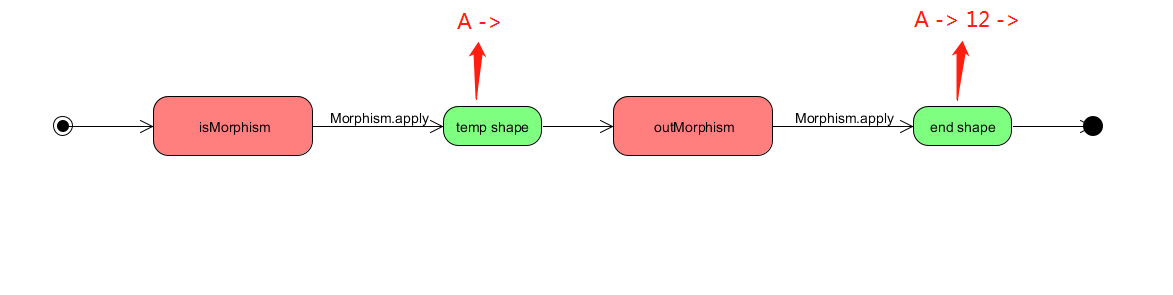
构造shape部分还包含了大量的shape优化 这部分复杂而内容很多 这里不展开
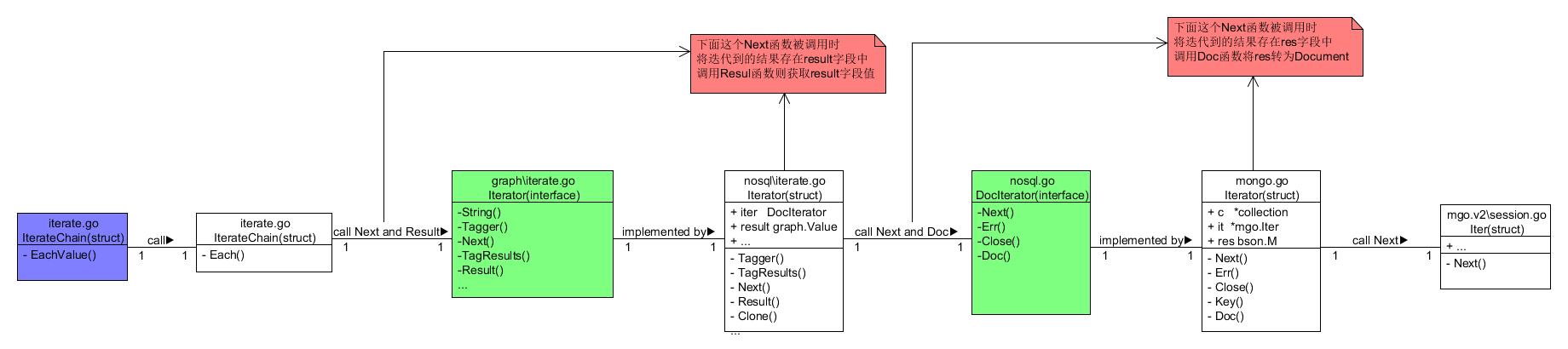
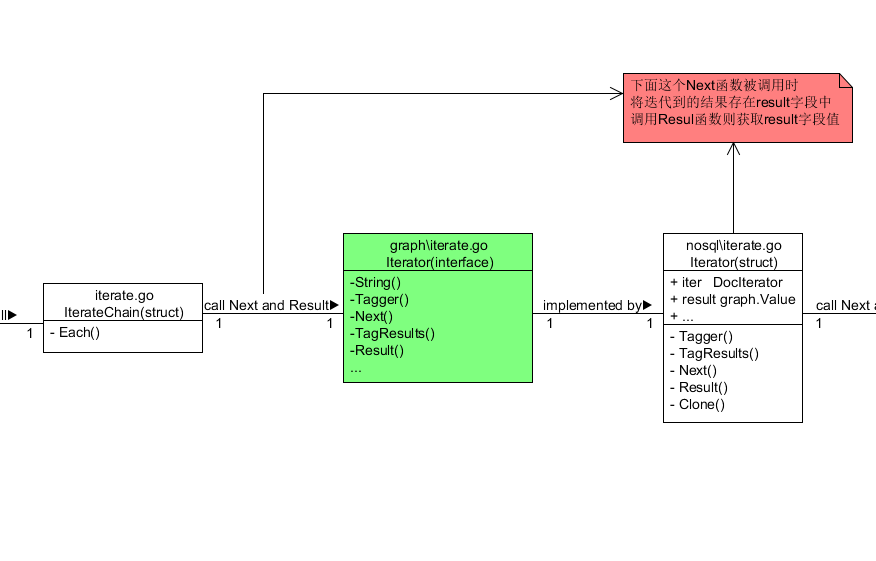
构造迭代器和迭代链
Iterator迭代器这个概念我们可以理解只负责某一部分计算工作的组件 cayley的查询设计是由若干个迭代器嵌套或者依次排列组合成的 呈现一个分布式结构 组合成的最终迭代器叫做IterateChain迭代器链 跟上面的shape一样 迭代的种类也是多种多样的 在这个分布式结构中的迭代器种类也不是都是类型一样的 所以宏观上我们不必关系具体使用了何种迭代器
cayley中对于迭代器的声明也是一个接口 在cayley中但凡实现了这个接口中所有方法的结构体我们都统称为迭代器Iterator
1 | type Iterator interface { |
上面最重要的迭代器方法就是
- Result() Value
- Next(ctx context.Context) bool
Next方法被这个迭代器用来执行内嵌在它自己内部的另一个迭代器 Result这个函数用来获取执行结果
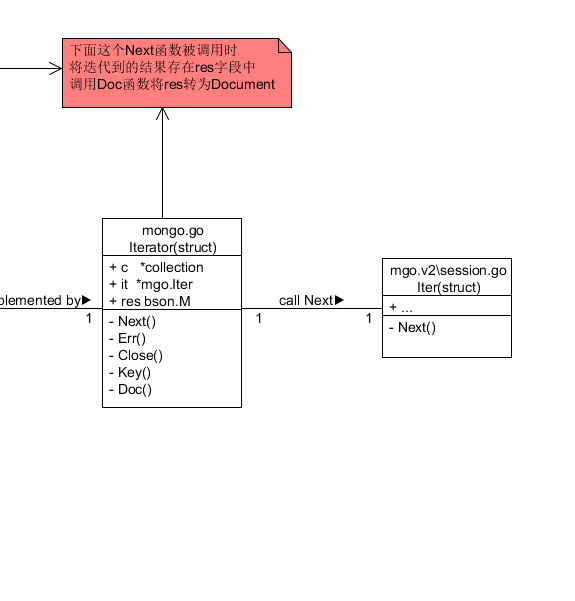
那么我们会很好奇迭代器这么抽象是怎样最终转化为mongodb的查询语句的呢?因为在cayley中使用的mongodb连接第三方包就是mgo.v2
其实我们知道迭代是一层一层嵌套的 那么我们可以看一下最底层的迭代器的结构 最底层的迭代器如下1
2
3
4
5
6
7
8
9
10
11
12
13
14type Iterator struct {
uid uint64
tags graph.Tagger
qs *QuadStore
collection string
limit int64
constraint []FieldFilter
links []Linkage // used in Contains
iter DocIterator
result graph.Value
size int64
err error
}
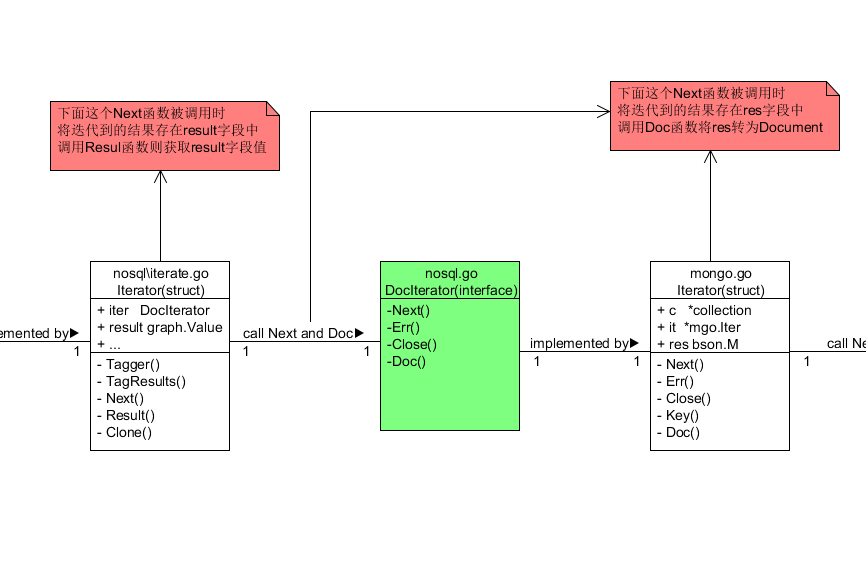
这个迭代是位于cayley源代码中的nosql\iterator.go中声明的迭代器 其中我们可以看到它包含一个字段
constraint []FieldFilter
FieldFilter在cayley定义如下1
2
3
4
5
6// FieldFilter represents a single field comparison operation.
type FieldFilter struct {
Path []string // path is a path to specific field in the document
Filter FilterOp // comparison operation
Value Value // value that will be compared with field of the document
}
Filter FilterO是一个用来表示比较的字段 有
- Equal
- NotEqual
- GT
- GTE
- LT
- LTE
Value Value就是存储的节点值
语义上 上面这个结构体可以根据比较大小的操作符FilterOp和它的值value 来转化为在mongodb中对图的具体某个节点的查询