relationship
relationship是sqlalchemy中的用于创建两个对象之间的关系的一个对象,跟原本的mysql没有太大关系,但是relationship一定要建立在具有外键关系的两个对象上
例如1
2
3
4
5
6
7
8
9
10class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key = True)
name = Column(String(20))
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key = True)
user_id = Column(Integer, ForeignKey("user.id"))
user = relationship("User", order_by = "Article.id", backref = backref("article"), cascade = "save-update, merge, delete")
user和article之间是一对多的关系,由于article具有
user = relationship("User", order_by = "Article.id", backref = backref("article"), cascade = "save-update, merge, delete")
字段,所以article具有user属性,也即article.user可以获取article对应的user
同时因为
backref = backref("article")
使得user具有article属性,由外键关系知道user和article为一对多关系,所以,user.article类型为[]。
backref和back_populates
stackoverflow上对两者的解释
If you use backref you don’t need to declare the relationship on the second table
就是使用backref就不用再两个具有外键的类上都声明relationship。
backref1
2
3
4
5
6
7
8
9class Parent(Base):
__tablename__ = 'parent'
id = Column(Integer, primary_key=True)
children = relationship("Child", backref="parent")
class Child(Base):
__tablename__ = 'child'
id = Column(Integer, primary_key=True)
parent_id = Column(Integer, ForeignKey('parent.id'))
back_populates1
2
3
4
5
6
7
8
9
10class Parent(Base):
__tablename__ = 'parent'
id = Column(Integer, primary_key=True)
children = relationship("Child", back_populates="parent")
class Child(Base):
__tablename__ = 'child'
id = Column(Integer, primary_key=True)
parent_id = Column(Integer, ForeignKey('parent.id'))
parent = relationship("Parent", back_populates="children")
上面两者是等价的
cascade级联
例子中
cascade = "save-update, merge, delete"
属性用来表示这两个关联起来的对象的增删的时候之间的关系
cascade默认值为save-update, merge
为了表达更清晰,声明了relationship属性的类我们称之为子类,没有声明的我们称之为父类,使用上面的user和article例子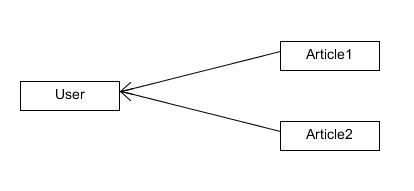
1.save-update
- 当user被add到session中的时候,两个article也自动被add到session中了
- 当article1被添加到session中时,user自动被添加进session,同时article2也会自动被添加进去
2.delete
- 当删除子对象时,父对象也一起被删除,如果子对象有指向父对象的外键且这个外键指向这个被删除的父对象,那么这个外键设置为null
- 当删除父对象时,子对象没有删除,如果子对象有指向父对象的外键且这个外键指向这个被删除的父对象,那么外键设置为null
3.delete-orphan
delete-orphan实在delete的基础上,加上当子对象被解除跟父对象的关系的时候就会被标志为删除
4.其他还有merge,refresh-expire,expunge那些不常用的就不要求理解了
测试代码
1 | from sqlalchemy import Column, String, Integer, ForeignKey, create_engine |