要点
- HashMap JDK1.7有哪些缺点,JDK1.8怎么改进的
- Hashmap扩容为什么要是2的整数次幂
- 手写HashMap的put流程图
上面几个问题是昆仑哥面试阿里的时候被问到的 所以这里我也围绕着三个问题去了解HashMap 文章后面会对这三个问题进行回答
HashMap关键字段
下面是一些HashMap初始化容量 扩容的阈值等重要字段1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24/**
* 默认的初始化容量大小 必须是2的n次方
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 最大容量
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默认负载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 当哈希表中一个槽的箱中装了8个元素 就将原来在这个箱中的链表转为红黑树
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 在resize过程中需要将箱子逆树化(红黑树->链表)的阈值?这个没看看到具体在源代码中在哪里使用到 所以不是很确定
*/
static final int UNTREEIFY_THRESHOLD = 6;
下面我们来看一下跟存储相关的字段1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29/**
* 整个哈希表 用数组来实现
*/
transient Node<K,V>[] table;
/**
* 存储着entrySet()的缓存 这里要注意keySet()和values()这两个重要方法其实是在HashMap的父类AbstractMap中的
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* 有多少对键值对
*/
transient int size;
/**
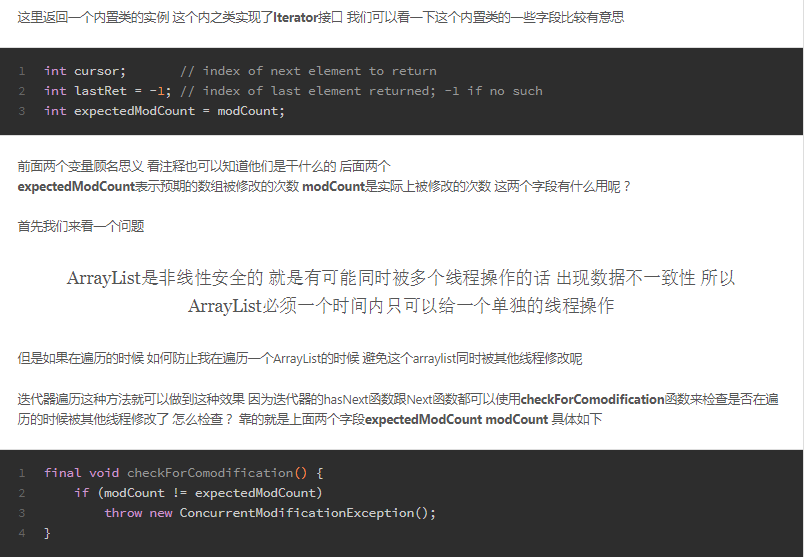
* HashMap不是线程安全的 这个字段主要是fast-fail机制中用来检测在遍历查询过程中HashMap是否被其他线程修改了
*/
transient int modCount;
/**
* 当哈希表打到阈值这个大小的时候 就扩容 threshold = capacity * loadFactor
*/
int threshold;
/**
* 负载因子 是哈希表中容量达到了 现容量*负载因子的时候就进行扩容 默认负载因子是0.75
*/
final float loadFactor;
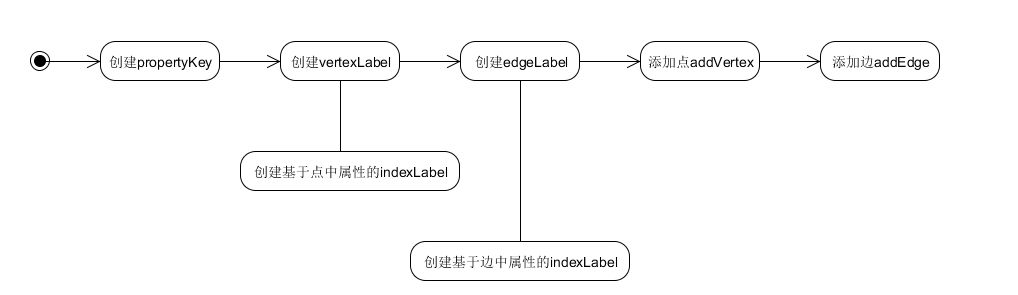
put流程
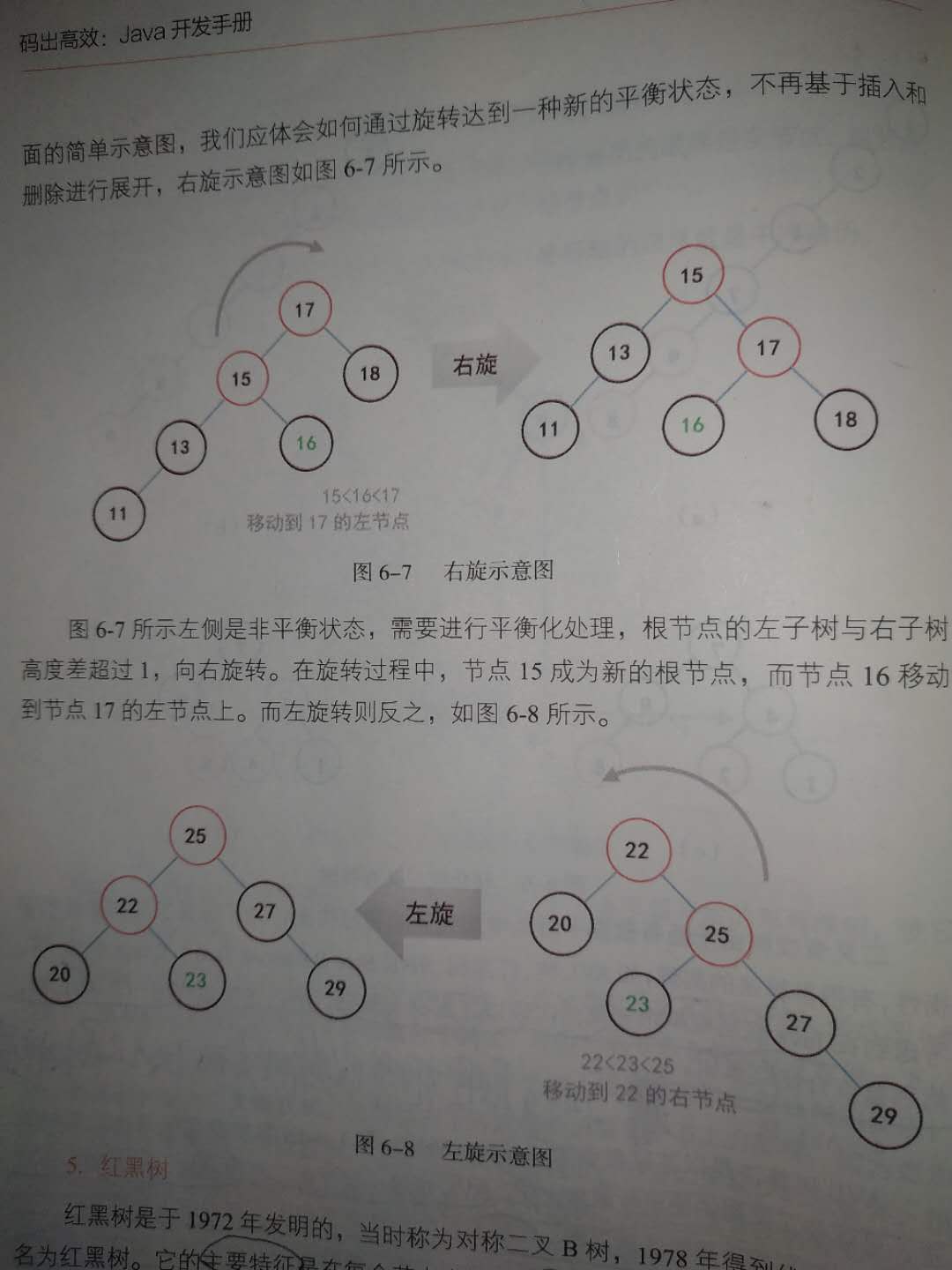
put流程很重要 我们可以通过HaspMap的put流程来了解HashMap的原理
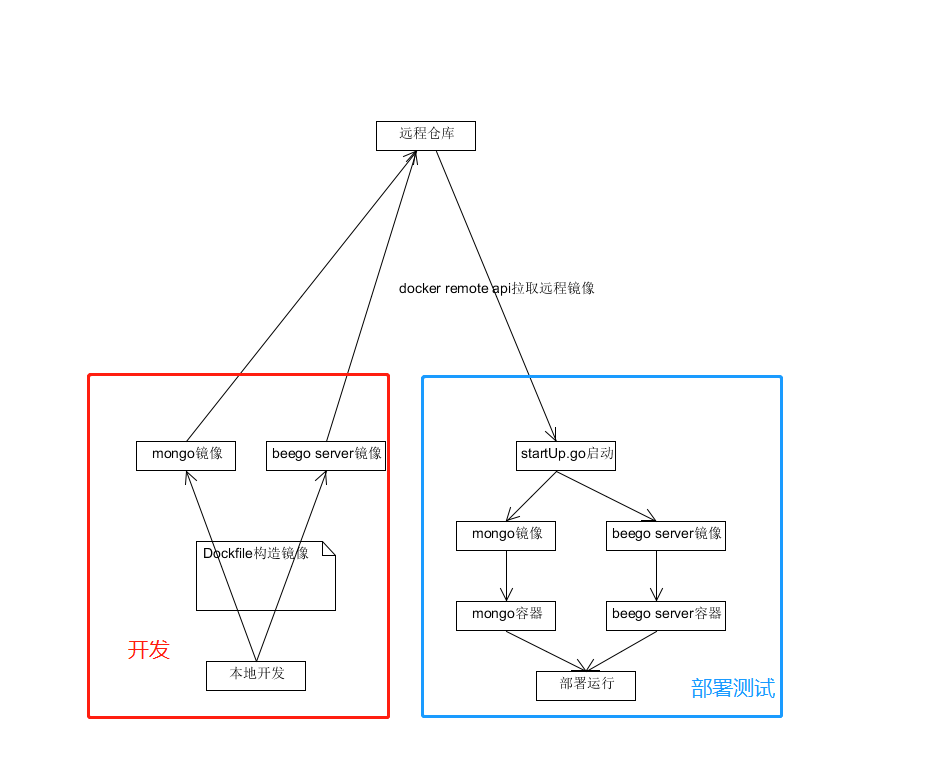
HashMap的机构是下面这样的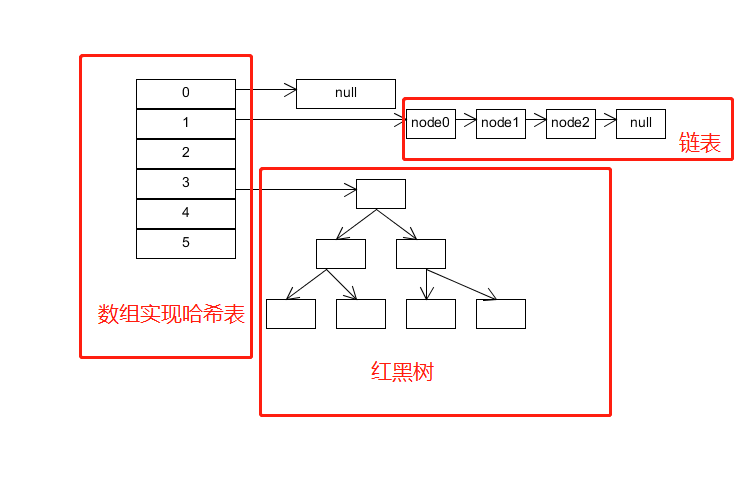
使用数组实现的哈希表 这个数组是会动态扩容的
动态扩容的条件是
- size是HashMap中所有元素的数量之和
- threshold等于capacity * load factor 也就是容量乘上负载因子
然后哈希表数组的每一个落槽点都会指向三种情况
- null
- 链表
- 红黑树
流程是这样的:
- 计算到落槽点之后 如果此处指向null 那么直接将新元素放置于此处
- 如果此处指向一个红黑树的节点 那么往红黑树的插入新的元素
- 如果此处指向一个链表节点 那么分两种情况 如果链表中节点数量低于树化阈值 直接插入链表 否则将链表转化为红黑树 然后插入新元素
所以上面的流程可以得到HashMap的put流程图
回答上面要点
- HashMap JDK1.7有哪些缺点,JDK1.8怎么改进的
- Hashmap扩容为什么要是2的整数次幂
- 手写HashMap的put流程图
1.第一个问题 HashMap JDK1.7有哪些缺点,JDK1.8怎么改进的
在JDK1.7中HashMap的底层结构都是数组实现一个哈希表 然后每个槽点指向一个链表 但是发展到JDK1.8之后 HashMap的底层存储是数组实现一个哈希表 每个槽点最开始指向一个链表 当打到阈值的时候会转化为一棵红黑树 然后往红黑树中插入新元素
由于上面再底层实现方面上 JDK1.7的HashMap查找的时间复杂度是O(1) + O(n) O(1)是哈希表的查找时间复杂度 O(n)是链表的查找时间复杂度 但是到了JDK1.8之后 由链表转化为红黑树 那么当HashMap中元素特别多的时候链表转化为红黑树 那么时间复杂度由O(n)转化为O(logn) 这样的话时间复杂度会降低不少 这就是JDK1.8中改进的地方
2.第二个问题 为什么扩容都是2的整数次幂
这个问题很有意思
我们来看一下 在HashMap中在哈希表中落槽位置的计算方式
也就是
(table.length - 1) & hash
如果table.leng是2^n的时候 有
(table.length - 1) & hash == hash % table.length
这样按位运算就会非常的快 这应该是JVM里面对于位运算有一些优化
3.第三个问题 上面我已经写了
HashMap Hello world
1 | class NewKey { |