暗网蜘蛛,本项目github地址

暗网
暗网(英语:Darknet或Dark Web)通称只能用特殊软件、特殊授权、或对电脑做特殊设置才能连上的网络,使用一般的浏览器和搜索引擎找不到暗网的内容
在python上进入暗网
在python中进入暗网需要配置tor代理,因为本人使用的win10,所以主要讲在win10下配置tor代理
下载准备:(除了下载给出的下载链接,本人此项目github也提供相关资源下载 下载链接)
下载到的tor expert bundle没有图形界面,使用起来不方便,因此需要下载Vidalia配合使用
本人提供的百度云链接,密码: kknfcow下载,百度云连接,密码: c4kx。
由于tor使用的协议是socks5,由于需要python的requests和selenium两个模块进行get, post请求。但是经过本人尝试,requests对socks5协议代理支持是很不良好的,使用requests加上socks5协议代理去get类似于 https://api.ipify.org/?format=json 这样查询ip的url是没有问题的,但是去get其他url或者暗网的url马上会出现莫名其妙的错误。所以需要使用cow把tor的socks5协议转为http协议
配置
我们要配置上面下载到的工具,使得我们的代理路线如下: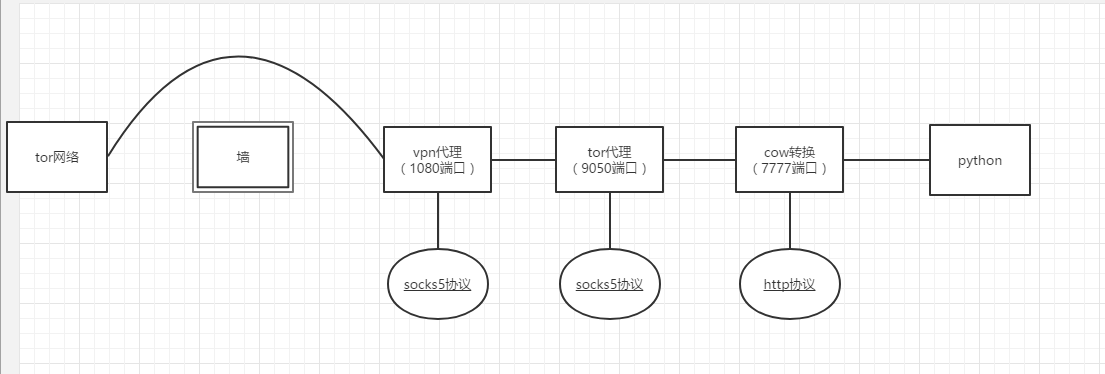
1,解压下载下来的tor expert bundle
2,开启你的vpn,本人使用的green vpn,socks5协议,监听1080端口
3,安装vidalia,安装后如图所示:
然后以管理员身份运行Start Vidalia.exe
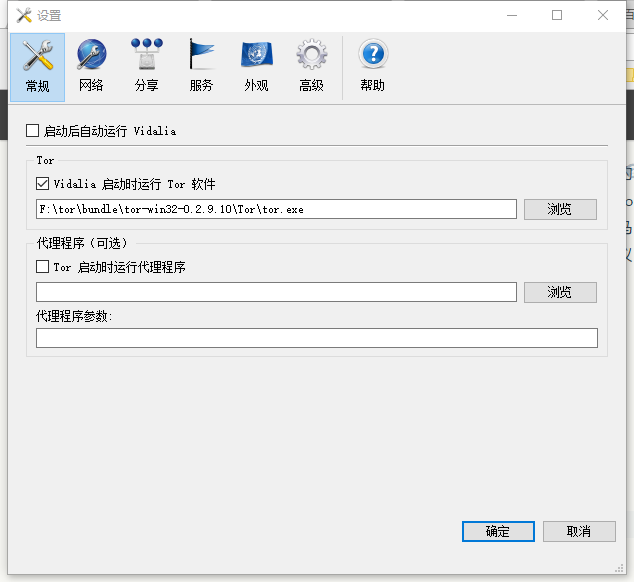
点击设定,在常规那里选中vidalia启动时运行tor软件,并在下面的路径中找到解压tor expert bundle后得到的tor.exe
点击网络,选中我使用代理服务器连接网络,由于本人使用的green vpn是监听本地的1080端口,所以地址写为:127.0.0.1,端口写为:1080(貌似shadowsocks等vpn也是监听本地1080端口)
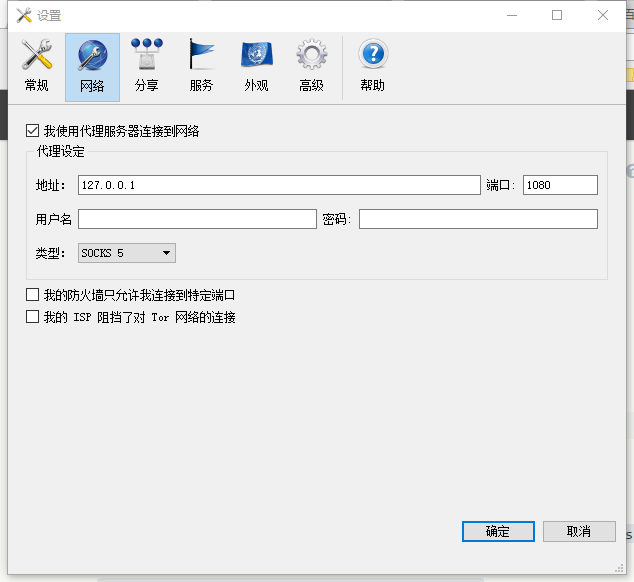
点击高级,在tor配置文件下选中vidalia安装后得到的Data/Tor/torrc文件,在数据目录那里选中Data文件夹(貌似我是多余地自己另外创建了一个Data文件夹给它,但是并不影响,有一个Data文件夹给vidalia存储数据就可以了)
点击确认
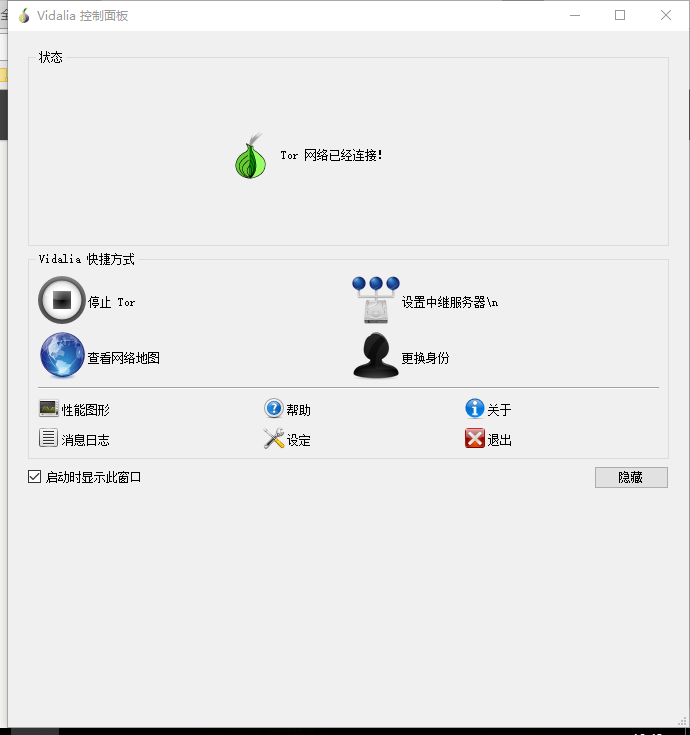
点击启动tor
稍等片刻,显示连接tor网络成功!
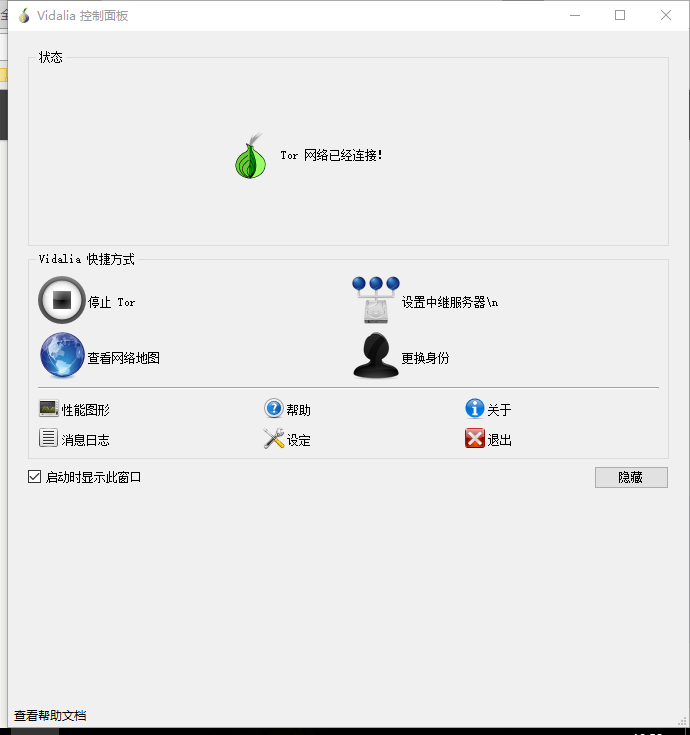
因为需要在requests模块上使用tor代理而requests模块对socks5支持非常不良好,所以我们需要配置cow把socks5转为http
打开解压后的cow目录:
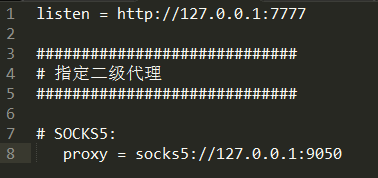
修改rc.txt内容为如下:
点击运行cow.exe或者点击cow-hide.exe后台运行
在python中使用tor代理
再次重申上面配置好的代理结构:
能否正常使用tor代理一个很好的检验方法就是能否进入暗网,这是一个收集了很多暗网url的网站:https://onionlinks.org/
我给出一个暗网url:http://hcutffpecnc44vef.onion/
这是一个暗网的金融网站,普通的上网方式是打不开的,作为一个大哥哥,真心建议18-的小朋友还是不要去看暗网一些其他内容,为了你的身心健康。那下面的测试就是在python中进入这个暗网url为检验标准。
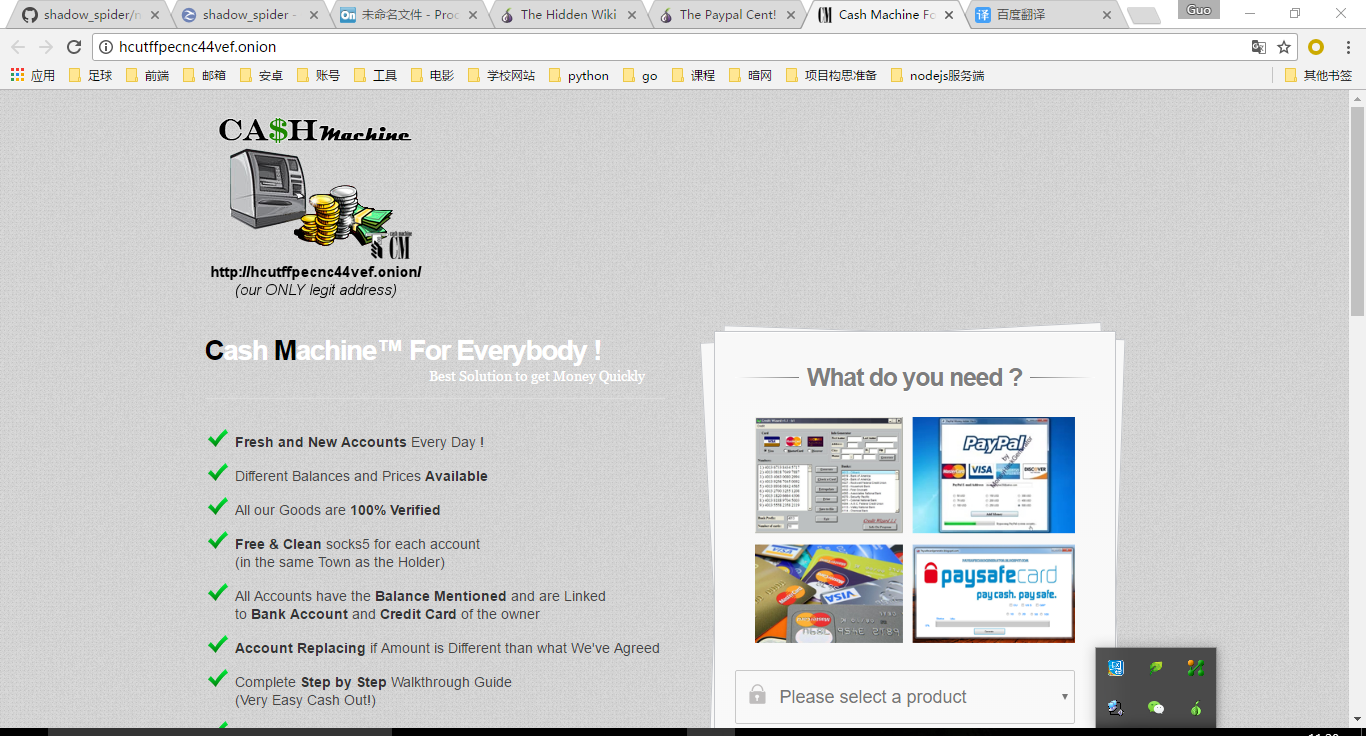
在requests中进入暗网:
新建一个test.py,输入以下内容:
import requests
proxies = {'http': 'http://127.0.0.1:7777', 'https': 'http://127.0.0.1:7777'}
s = requests.Session()
r = s.get("http://hcutffpecnc44vef.onion/", proxies = proxies)
print(r.text)
f = open("onion.html", "wb")
f.write(r.content)
f.close()
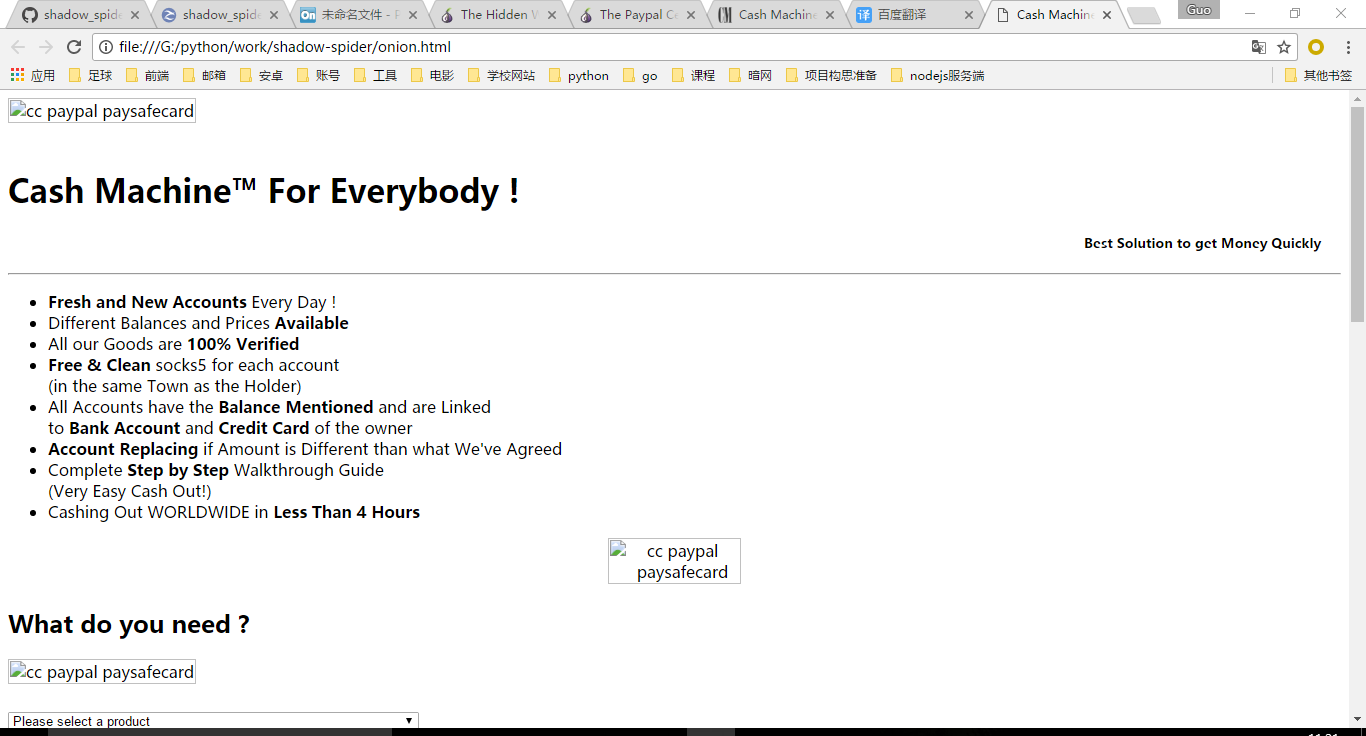
运行,发现可以打印这个暗网网页的内容出来了:
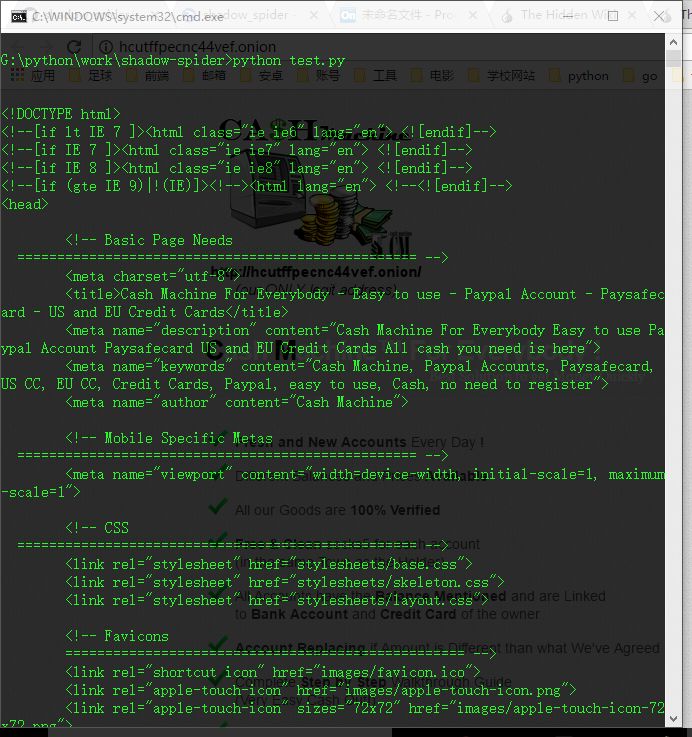
打开test.py同一目录下,生成了一个onion.html的文件,点开,发现把内容也下载下来了:
在python的selenium模块的模拟浏览器phantomjs中进入暗网
selenium有三种,chrome,firefox,phantomjs,前两种有图形界面,第三种没有图形界面,所以我选中phantomjs
phantomjs下载:
本人github上的下载下载链接
本人百度云下载链接,密码: pj81
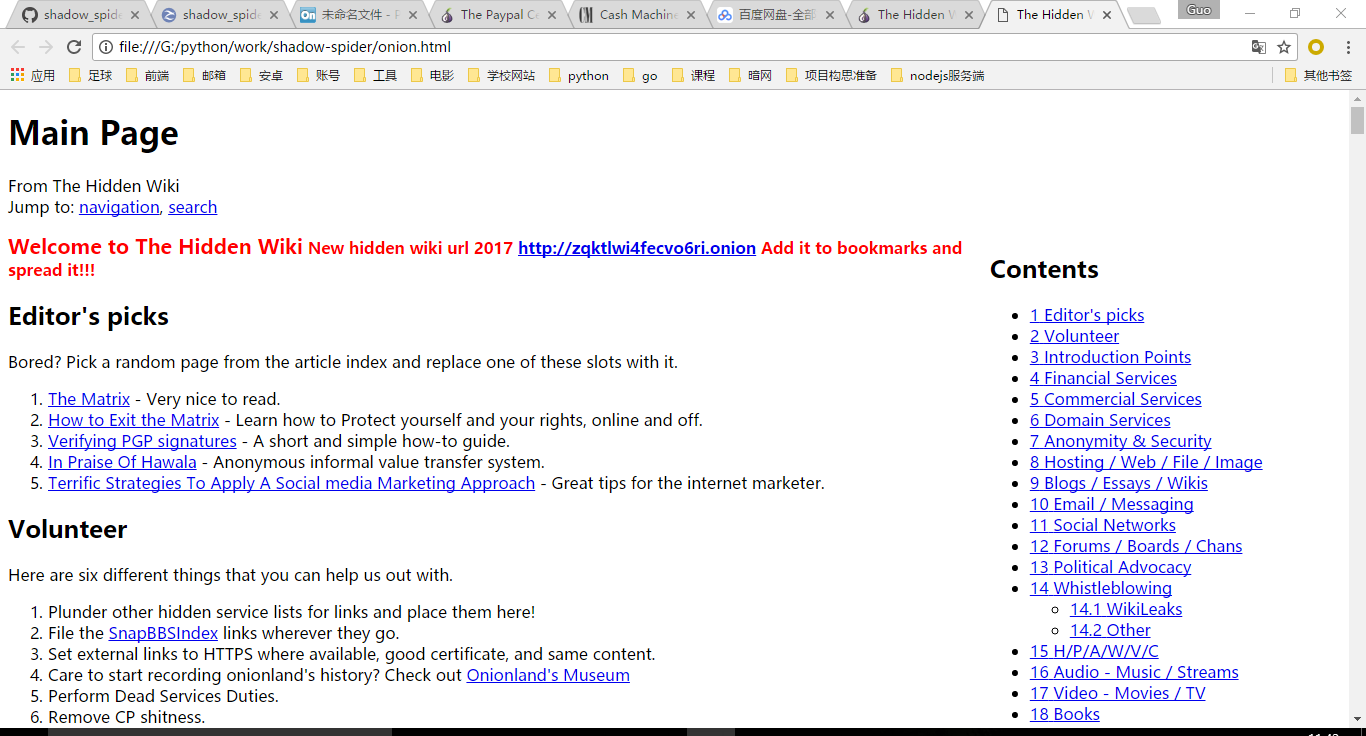
这次我们选择另一个暗网url:http://zqktlwi4fecvo6ri.onion/wiki/index.php/Main_Page
这是一个暗网wiki,上面有很多分类好的暗网url,各位要谨慎点开那些url,因为不少内容不健康的。
下载phantomjs解压,新建一个test2.py文件(下面的executable_path是上面下载解压phantomjs得到的phantomjs.exe运行文件的路径)
from selenium import webdriver
executable_path = "C:/Users/Administrator/Downloads/phantomjs-2.1.1-windows/phantomjs-2.1.1-windows/bin/phantomjs.exe"
service_args = ['--proxy=127.0.0.1:7777', '--proxy-type=http']
driver = webdriver.PhantomJS(executable_path = executable_path, service_args = service_args)
driver.get("http://zqktlwi4fecvo6ri.onion/wiki/index.php/Main_Page")
print(driver.page_source)
f = open("onion.html", "wb")
f.write(driver.page_source.encode("utf-8"))
f.close()
结果也可行:
本人的shadow_spider项目(未完待续)
项目github地址
本项目目的在于最大程度还原暗网上网页的内容,这就意味着需要:
注意要点:
- 下载html
- 在下载html之前必须加载javascript。因为javascript里面会有ajax,如果把javascript下载下来,而不是加载完javascript再下载html,那么下载到本地ajax向tor网络(暗网)中的服务器发送网络请求,这是行不通的。所以必须加载完javascript再下载html(网上有人说暗网上的网页都没有javascript,但是经本人尝试,暗网上的网页是有javascript的)。而python里加载javascript一个很好的工具就是上面的selenium
- 下载css和图片等静态资源,需要使用requests模块,不能使用selenium。selenium下载图片和css等资源是很蛋疼的。因为这些模拟浏览器要下载资源就必须做到模仿我们在真的浏览器上那样右键另存为等操作,而这时候会弹出下载确认的弹窗,而selenium中的chrome和firefox是需要手动点击代码运行过程中弹出来的确认保存弹窗的,而phantomjs没有图形界面,所以就根本下载不图片和css等资源。
代码细节不详细说了,在我的github中下载到本地,输入:
pip install -r requirements.txt
安装需要的响应模块
运行main.py文件,输入一个暗网url:
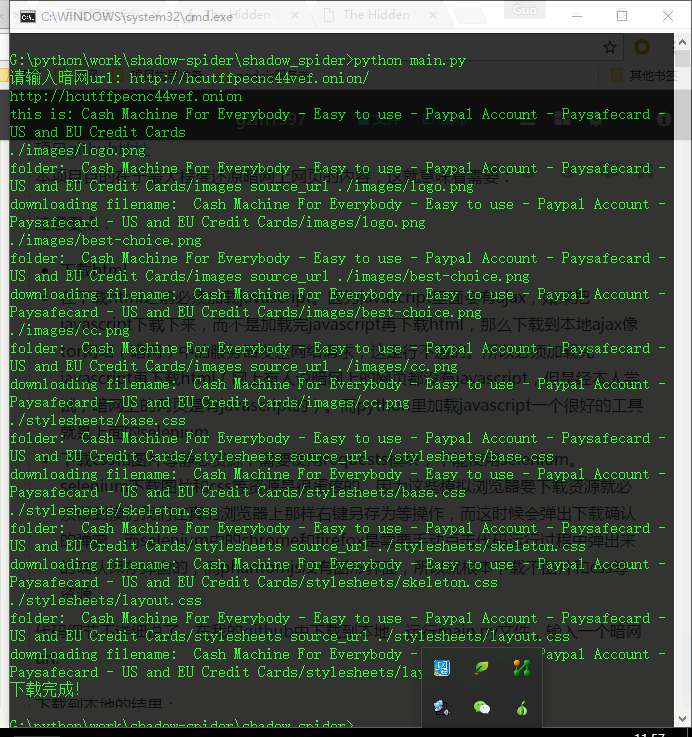
下载到本地的结果:
下面是一些暗网网页真实模样和我还原的样子:
真实1:
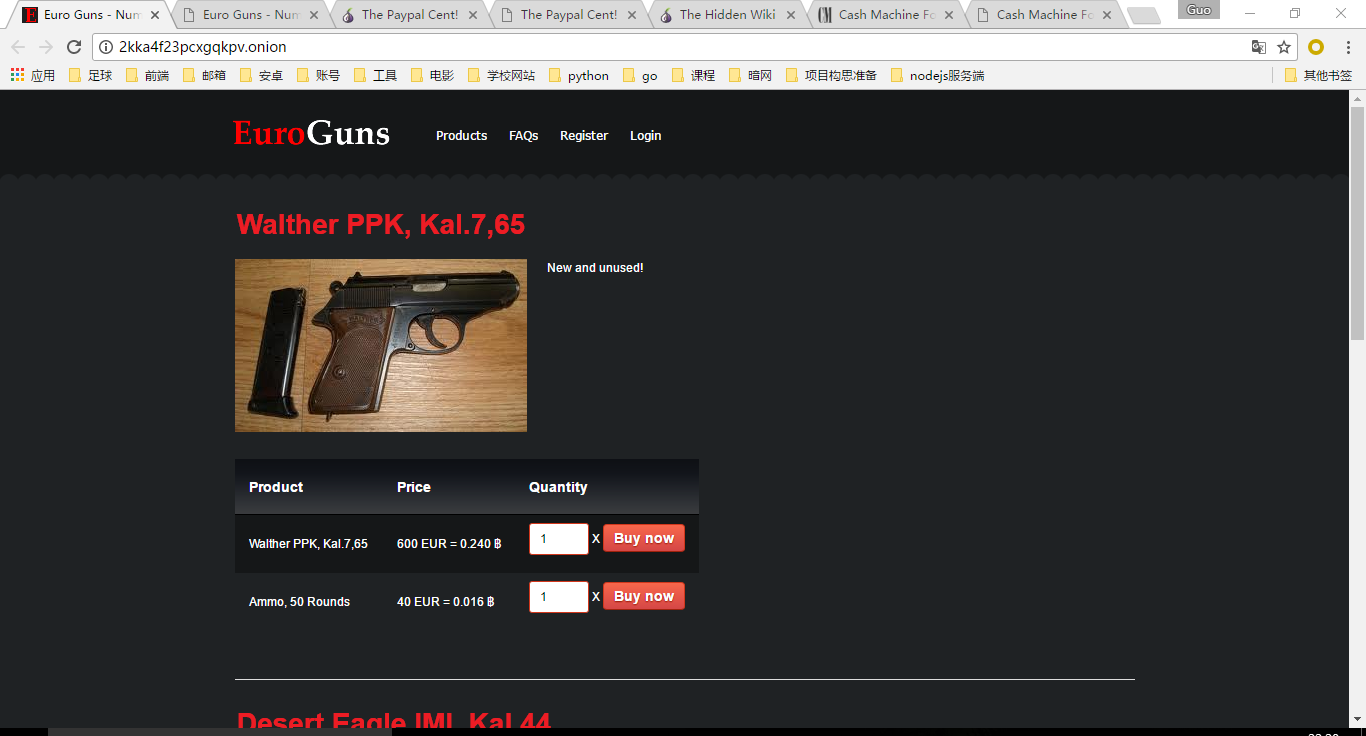
还原1:
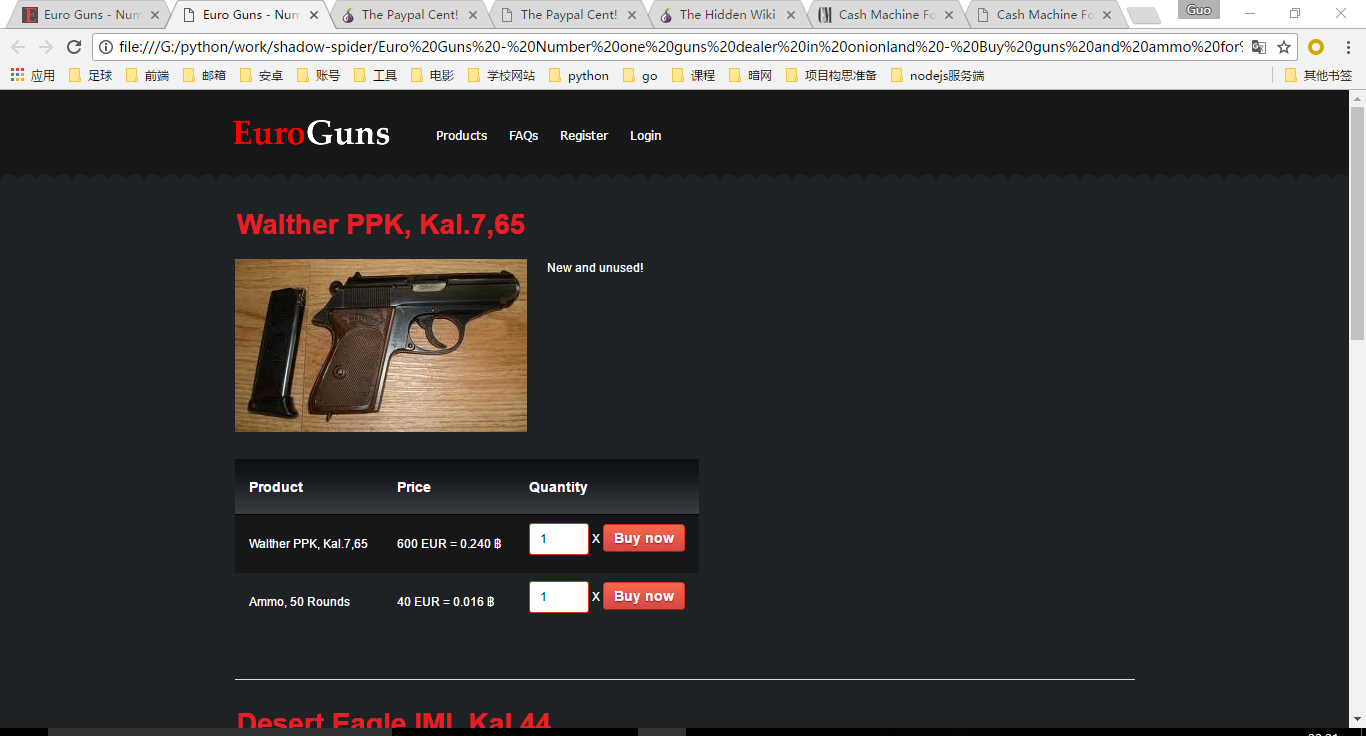
真实2:
还原2:
此项目shadow_spider未完待续,等到暑假回考虑添加服务端。