郭柱明
图数据库背景
在此之前已经简单记录了一下图数据的背景和发展现状 图数据引擎那部分现在还是知之甚少 还没深入去了解
图数据库背景
cayley优点
- go语言实现
- 运行简单(三四条命令)
- 支持http接口以及REPL交互式
- 支持多种语言进行查询
- Gizmo
- MQL
- GraphQL
- 支持多种后端存储
- KVs: Bolt, LevelDB
- NoSQL: MongoDB, ElasticSearch, CouchDB/PouchDB
- SQL: PostgreSQL, CockroachDB, MySQL
- n-memory, ephemeral
- 模块化编程 容易拓展
- 良好的测试覆盖
- 速度快
- 免费
运行和应用
这里真的要非常注意 因为cayley提供的官方文档相当有限 会导致很多新手搞不清到底怎么使用这个图数据
cayley使用两种方式
- 作为应用运行使用
- 作为第三方库运行使用
作为应用运行使用
下面是官方文档中作为应用进行运行使用的部分
参考链接
- 下载二进制文件解压或者下载源码进行编译
- 配置
- 导入数据
- 运行
运行使用一下命令
./cayley http --config=cayley.yml --host=0.0.0.0:64210
或者在Linux系统下后台运行
./cayley http --config=cayley.yml --host=0.0.0.0:64210 &
可以看到已经在后台运行 监听64210端口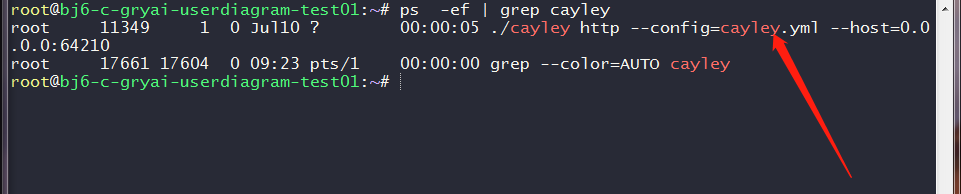
上面这种运行方式是使用一个go原生net/http架起一个web服务器 以方便开放人员作为管理员可以在web界面上使用UI进行数据库的增删查找 如下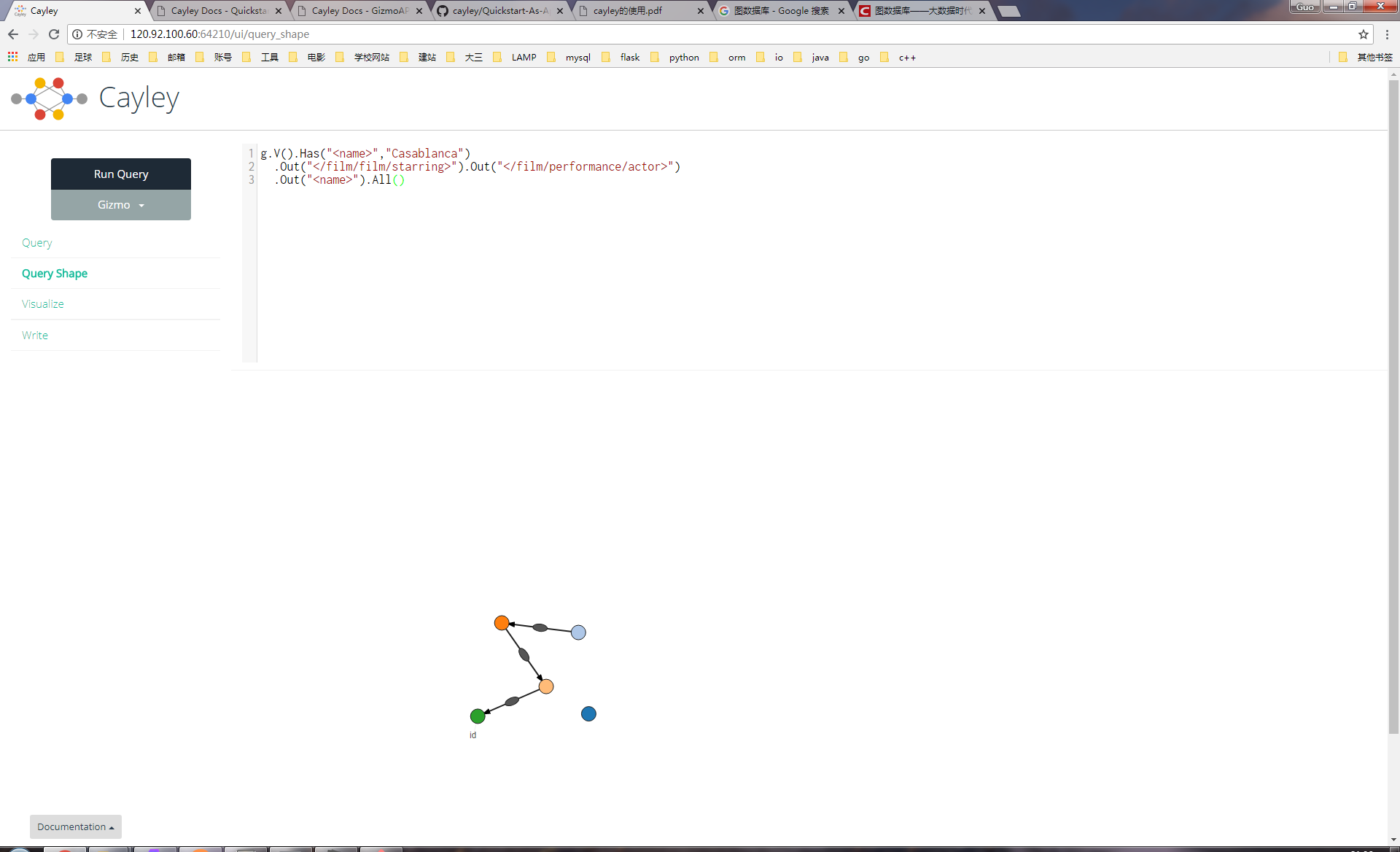
但是 对于这个http接口 官方并没有提供进一步的封装 意味着如果你要使用这种方式运行cayley 并且在你的项目中连接这个数据库 那么你是需要自己拼凑我们用来增删查找的Gizmo语句(如果选择使用Gizmo) 类似以下1
2
3g.V().Has("<name>","Casablanca")
.Out("</film/film/starring>").Out("</film/performance/actor>")
.Out("<name>").All()
然后post给服务端上的cayley
这就意味着你需要进一步封装这个http接口 就跟写一个爬虫一样 虽然在Python上已经有人做好了这部分工作
pyley一个封装了cayley http接口的客户端
但是go语言我目前还没发现有类似的 官方亦然
作为第三方库运行使用
我个人推荐将cayley作为第三方库来进行运行 一个是go get安装cayley第三方库的时候就顺带安装了cayley 因为cayley本身就是go编写的 但是这方面的使用官方文档上简直坑得不行 仅仅提供了几个hello world 对刚接触的开发者来说真的非常不友好
官方提供的几个example
hello_world和transaction都是使用
cayley.NewMemoryGraph()
这个api使用内存作为临时的存储位置进行存储的
hello_bolt和hello_schema都是使用一个叫bolt的键值对数据库进行存储的 这个需要一个路径来存存储着数据的文件
除此之外 官方文档就没提供太多 实际在go语言中链接cayley的方式了
但是我们小组的领导决定使用mongodb作为backend进行存储 上面的例子都没有太大的实际应用意义
我参照了bolt作为backend的例子修改了一下 获得了使用mongodb作为backend的方法
注释已经将每一部分讲的很清楚了 所以就不说其他什么了
1 | package main |
输出
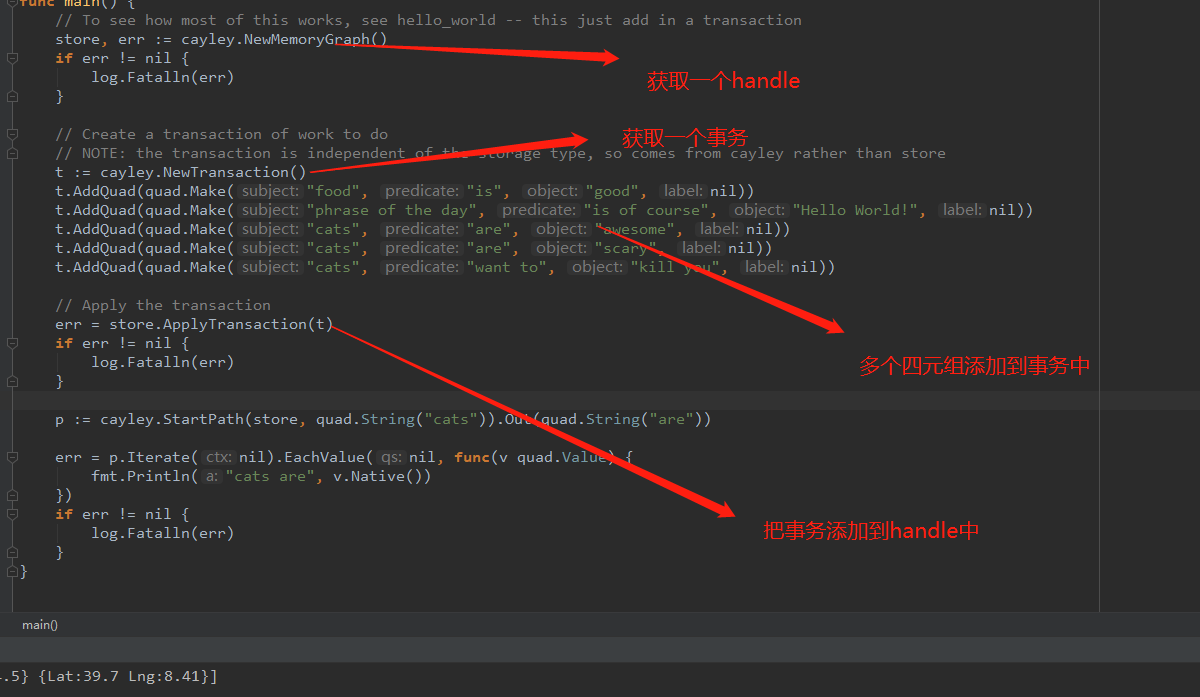
事务
- 初始化数据库获取一个handle
- 获取一个事务
- 添加多个四元组到事务中
- 将事务添加到handle中
- 查询跟之前没什么区别
数据结构与api
1.添加四元组的方式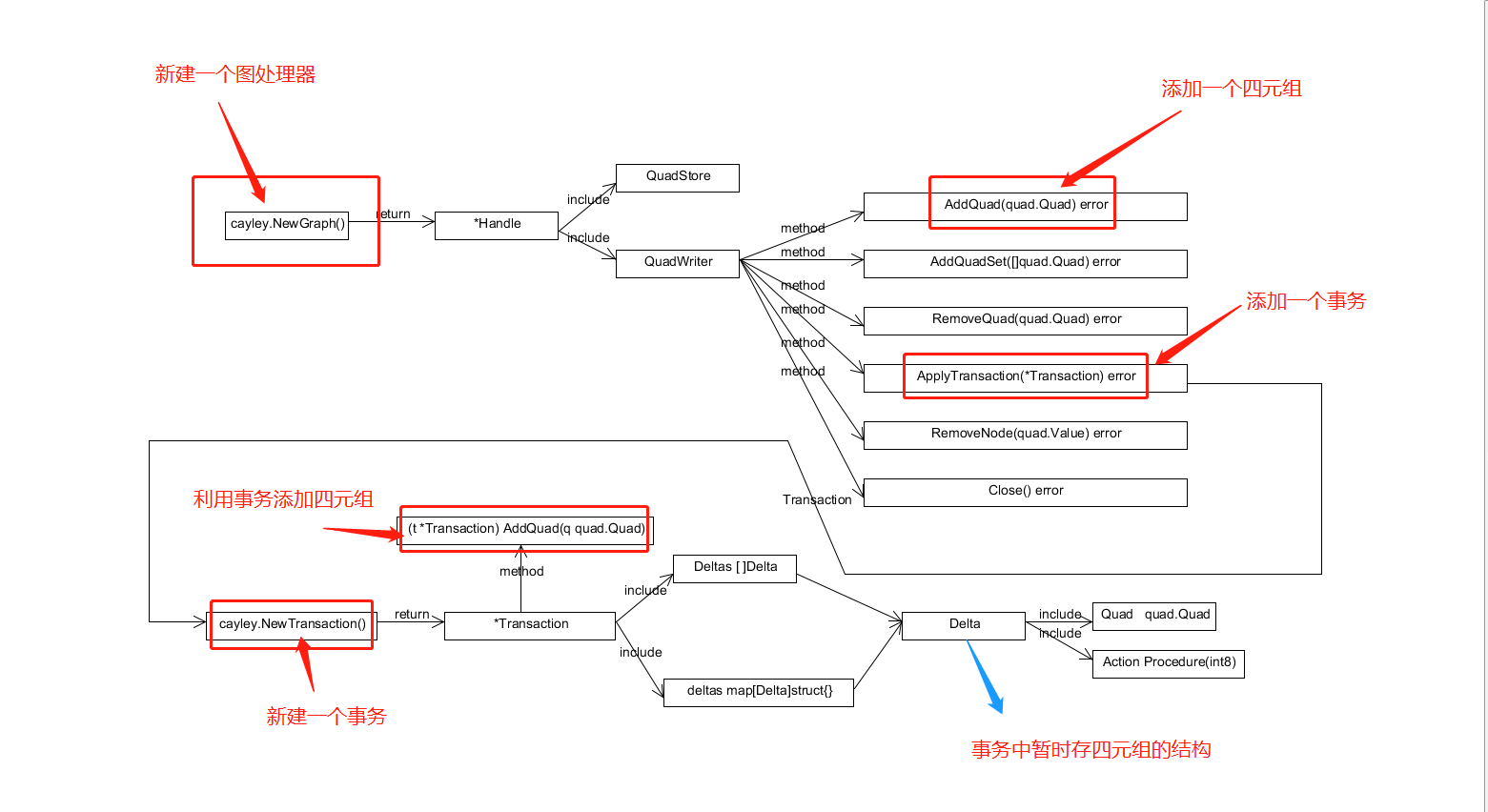
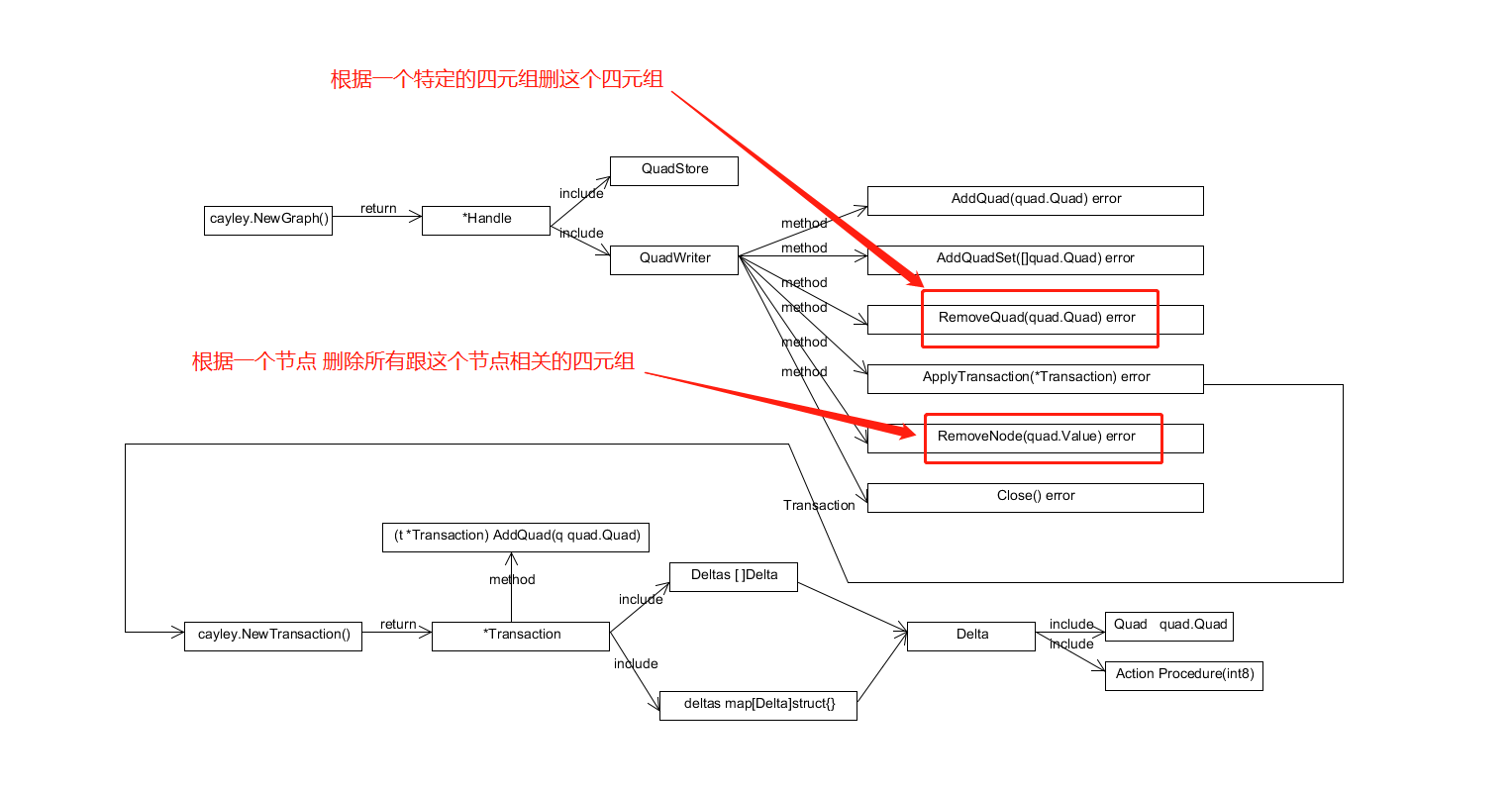
2.更新或者删除四元组
cayley的设计中是没有更新四元组这个api 如果想要更新一个四元组只能先删除这个四元组 然后再重新添加一条新的四元组
数据集

cayley api
四元组 含有主谓宾标签1
2
3func Quad(subject, predicate, object, label interface{}) quad.Quad {
return quad.Make(subject, predicate, object, label)
}
三元组 含有主谓宾 没有标签(标签为nil)1
2
3func Triple(subject, predicate, object interface{}) quad.Quad {
return Quad(subject, predicate, object, nil)
}
处理器handle1
type Handle = graph.Handle
一个handle的结构是1
2
3
4type Handle struct {
QuadStore
QuadWriter
}
包含一个匿名的四元组存储成员 一个匿名的四元组写入成员
新建一个处理器1
func NewGraph(name, dbpath string, opts graph.Options) (*Handle, error)
返回一个handle
新建一个内存存储的处理器1
func NewMemoryGraph() (*Handle, error)
从它的具体实现 可以知道这基于memstore内存进行存储的处理器1
2
3func NewMemoryGraph() (*Handle, error) {
return NewGraph("memstore", "", nil)
}
迭代器1
type Iterator = graph.Iterator
query path1
type Path = path.Path
Gizmo
因为我们上面都是使用Gizmo作为查询语言进行查询的 所以很有必要记录一下Gizmo的基本语法
基本语句太多了 所以只简要记录一下常用的语句
1.
graph.M()
是
graph.Morphism()
的缩写 Morphism创建一条路径 这样允许Gizmo的路径可以被复用
类似如下
var shorterPath = graph.Morphism().Out("foo").Out("bar")
2.
graph.V(*)
是
graph.Vertex([nodeId],[nodeId]...)
的缩写 这个语句返回一个根据给定的点作为始点的query path 没有nodeID的话以为着所有的点
3.
Path object .Morphism()和.Vertex()和这个函数都可以创建一个query path对象
4.
path.And(path)
是
path.Intersect(path)
的缩写 就是逻辑与的意思
例子1
g.V("<charlie>").Out("<follows>").And(g.V("<dani>").Out("<follows>")).All()
5.
path.As(tags)
是
path.Tag(tags)
的缩写
Tag保存一个list的nodes存到给定的tag 主要是为了保存我们的工作或者为了了解一个path是怎样到达终点的 我们需要这个tag来进行标志一下
6.
path.Back(tag)
跟tag来后退到tag上面去
7.
path.Both([predicatePath], [tags])
获取同时进来和出去的节点
例子1
g.V("<fred>").Both("<follows>").All()
8.
path.Count()
返回结果的数量
9.
path.Difference(path)
是
path.Except(path)
的别名
Except移除当前path上匹配了这个query path删的所有paths
10.
path.Follow(path)
是一种使用.Morphism()准备好的query path的方式
11.
path.ForEach(callback) or (limit, callback)
遍历query path
12.
path.Has(predicate, object)
一般应用于所有节点或者一个堆节点按照某个谓语进行查询 例子1
g.V().Has("<follows>", "<bob>").All()
13.
path.In([predicatePath], [tags])
in就比较直观了 就是按照这个谓语进来到这个节点
path.Out([predicatePath], [tags])
类似 就是按照这个谓语出来这个节点
14.
path.Or(path)
是
path.Union(path)
别名
这个也比较直观 就是逻辑或
15.
path.Save(predicate, tag)
保存所有使用这个谓语进入这个tag的节点 并且不遍历