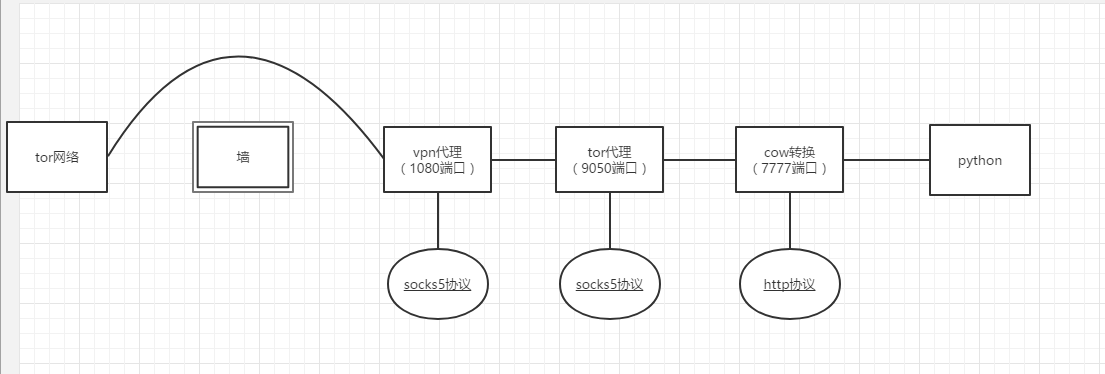
gzm keep patient
java和编译型语言区别
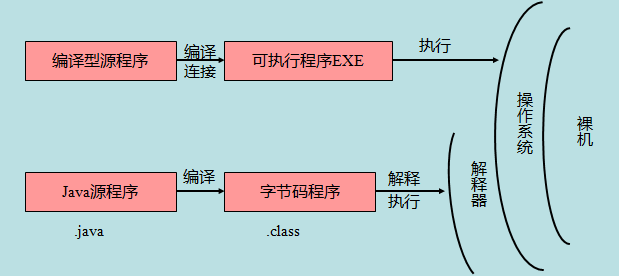
编译型语言直接编译变为可执行程序exe,然后就可以执行了。但是java需要先编译为.class字節碼,在由解釋器進行解釋執行。可以說java是介於編譯型語言和解釋型語言之間的一鍾語言了。所以網上一直有種說法:最好不要使用編譯型語言和解釋型語言的劃分方法來劃分java,因爲它既有編譯,也有解釋。
各种类型变量存储位置
局部变量 -> 栈
动态变量 -> 堆
全局变量 静态变量 -> 静态存储区
函数代码 -> 代码区
常量 -> 常量区
java支持的变量类型
类中的变量类型
- 类变量 独立于方法之外的变量 static修饰 每个类共享
- 实例变量 独立于方法之外 但是没有static修饰 每个实例都有自己的一个这个变量的版本 实例变量具有默认值。数值型变量的默认值是0,布尔型变量的默认值是false,引用类型变量的默认值是null 变量的值可以在声明时指定,也可以在构造方法中指定
- 局部变量 类方法中的变量 访问修饰符可以修饰实例变量
局部变量
- 声明在方法、构造方法或者语句块中
- 访问修饰符不能用于局部变
- 局部变量是没有默认值 所有被声明之后需要初始化之后才可以使用
final修饰变量
final 变量能被显式地初始化并且只能初始化一次。被声明为 final 的对象的引用不能指向不同的对象。但是 final 对象里的数据可以被改变。也就是说 final 对象的引用不能改变,但是里面的值可以改变
final修饰类中的方法
类中的 final 方法可以被子类继承,但是不能被子类修改。
final修饰类
final修饰的类不能被继承 没有类能继承final类的任何特性
abstract修饰符
abstract抽象类是不能用来实例化对象的 声明抽象类的唯一目的就是将来对该类进行扩充
如果一个类中具有抽象方法 那么这个类一定要声明微抽象类 抽象方法的的定义由子类提供
任何继承抽象类的子类必须实现父类的所有抽象方法,除非该子类也是抽象类。
abstract抽象类例子
Test.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17abstract class Mon_class {
public abstract void m();
}
class Son_class extends Mon_class {
public void m() {
System.out.println("this is a m func");
}
}
public class Test {
public static void main(String []args) {
Son_class test_class = new Son_class();
test_class.m();
}
}
可以使用非抽象子类的构造函数创建一个抽象父类的引用对象 并且可以调用具体定义在非抽象子类中的重写方法
但是注意非抽象类的构造函数并不可以用来创建一个实例
synchronized 修饰符
synchronized 关键字声明的方法同一时间只能被一个线程访问。synchronized 修饰符可以应用于四个访问修饰符。
transient 修饰符
序列化的对象包含被 transient修饰的实例变量时,java虚拟机(JVM)跳过该特定的变量。
该修饰符包含在定义变量的语句中,用来预处理类和变量的数据类型。
volatile 修饰符
volatile 修饰的成员变量在每次被线程访问时,都强制从共享内存中重新读取该成员变量的值。而且,当成员变量发生变化时,会强制线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
一个 volatile 对象引用可能是 null。
extends和implements
- 在类的声明中,通过关键字extends来创建一个类的子类。一个类通过关键字implements声明自己使用一个或者多个接口。
extends 是继承某个类, 继承之后可以使用父类的方法, 也可以重写父类的方法; implements 是实现多个接口, 接口的方法一般为空的, 必须重写才能使用
2.extends是继承父类,只要那个类不是声明为final或者那个类定义为abstract的就能继承,JAVA中不支持多重继承,但是可以用接口 来实现,这样就要用到implements,继承只能继承一个类,但implements可以实现多个接口,用逗号分开就行了
instanceof运算符
1 | public class Test { |
装箱和拆箱
在java中的内置数据类型对应的包装类都是继承一个叫做Number的抽象类的,关系图如下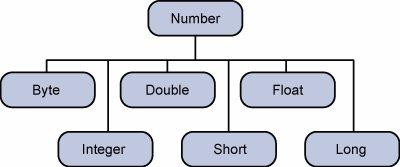
- 当内置数据类型被当作对象使用的时候 编译器会吧内置类型装箱
- 反过来 编译器也会一个包装类拆箱
比如下面是整型包装类和内置类型之间的装箱和拆箱之间的关系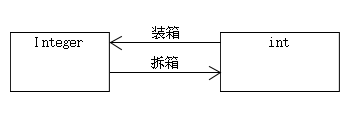
例子1
2
3
4
5
6
7
8
9public class Test {
public static void main(String []args) {
//装箱
Integer num = 5;
//拆箱
num += 10;
System.out.println("num " + num);
}
}
Charactor
char这个内置数据类型对应的包装类是Charactor
String和char array
String和char array的相互转换以及遍历
String转为char array1
2String t_str = "abcd";
char [] c_arr = t_str.toCharArray();
char array转为String1
String new_str = new String(c_arr);
foreach只可以用来迭代可迭代对象 String并不是可迭代对象 只有char array是可迭代对象1
2
3
4
5
6
7
8for (char c: c_arr
) {
System.out.println(c);
}
for (char c: new char[]{'1', '2', '3'}
) {
System.out.println(c);
}
String类是不可该改变的 即使具有concat那些字符串连接方法 但是那也是新建了一个新的String对象 如果需要改变字符串 那么就需要使用StringBuffer和StringBuilder对象了
- String 不可修改 速度最慢
- StringBuffer 可修改 速度中等 线程安全
- StringBuilder 可修改 速度最快 非线程安全
StringBuffer基本使用
(注意在insert和replace这些函数中 start end的范围是跟python是相同 都是包含start但是没有包含end)1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Test {
public static void main (String []args)
{
StringBuffer test_buffer = new StringBuffer("lala");
test_buffer.append("heihei");
System.out.println(test_buffer);
test_buffer.reverse();
System.out.println(test_buffer);
test_buffer.delete(test_buffer.length() - 3, test_buffer.length());
System.out.println(test_buffer);
test_buffer.replace(1, 2, "heihei");
System.out.println(test_buffer);
}
}
StringBuilder
如果在StringBilder的构造函数中没有传入一个长度参数,那么这个构造函数将会为这个StringBuilder分配默认的16个字符的空间
什么是内存抖动Memory Churn
内存抖动是因为大量对象被创建又在段时间内马上被释放 内存页被频繁更换 导致整个系统效率急剧下降 这个现象称为内存抖动 一般都是因为内存分配算法不好 内存太小造成的
其实内存抖动就是系统颠簸
正则表达式
基本使用1
2
3String content = "i am haha";
String patern = ".*haha";
System.out.println(Pattern.matches(patern, content));
常用的正则表达
- .表示任意一个字符
- \s+表示若干个空格(应该是1个或者多个)
- \d+表示一个或者多个数字
- \.表示.
- ()?表示问好前面中的括号的内容是可选的
- {n} n为非负数 表示前面的字符刚好重复n次
- {n,} n为非负数 表示前面的字符至少重复n次
- {n,m} n为非负数 表示前面的字符出现次数至少n次 之多m次
- x|y 匹配x或者y
- [xyz]匹配xyz中任一字符
- [^xyz] 跟上面的相反 匹配不是xyz的字符
- [a-z] 字符范围 匹配a-z之间的字符
- [^a-z]反向范围
- \b匹配一个字符边界(字符和空格间的位置) 例如,”er\b”匹配”never”中的”er”,但不匹配”verb”中的”er”。
- \B匹配一个非字符边界 “er\B”匹配”verb”中的”er”,但不匹配”never”中的”er”。
java可变参数
从jdk1.5开始 java支持传递同类型的可变参数 这个跟声明参数为数组类型的不同的地方在于可以传入多个同类型的参数
声明方式
typeName... parameterName
例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Test {
public static void testPrint(int... arr) {
if (arr.length == 0) {
System.out.println("no parameter has been transfer");
}
for (int i: arr
) {
System.out.println(i);
}
}
public static void main(String []args) {
testPrint(1, 2, 3, 4);
testPrint(new int[] {3, 2, 1});
}
}
收尾机制finalize
例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Dog extends Object {
int id;
Dog(int _id) {
id = _id;
System.out.printf("id %d dog is create\n", id);
}
protected void finalize() throws java.lang.Throwable {
super.finalize();
System.out.printf("id %d dog is dispose\n", id);
}
}
public class Test {
public static void main(String []args) {
Dog d1 = new Dog(1);
Dog d2 = new Dog(2);
//Dog d3 = new Dog(3);
//d1 = null;
//System.gc();
d1 = d2 = null;
System.gc();
}
}
java io
从控制台中输入一个字符1
2
3
4
5
6
7
8
9
10
11
12import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Test {
public static void main(String []args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int r = br.read();
char c = (char) r;
System.out.println(c);
}
}
在控制台中输入一个字符串 也是使用Bufferreader这个对象进行读取 但是是使用readline这个函数进行读取1
2
3
4
5
6
7
8
9
10
11import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Test {
public static void main(String []args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String r = br.readLine();
System.out.println(r);
}
}
可以解决中文输入输出出现乱码都解决方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47import java.io.*;
public class Test{
public static void main(String[] args) throws IOException {
File f = new File("a.txt");
FileOutputStream fop = new FileOutputStream(f);
// 构建FileOutputStream对象,文件不存在会自动新建
OutputStreamWriter writer = new OutputStreamWriter(fop, "UTF-8");
// 构建OutputStreamWriter对象,参数可以指定编码,默认为操作系统默认编码,windows上是gbk
writer.append("中文输入");
// 写入到缓冲区
writer.append("\r\n");
//换行
writer.append("English");
// 刷新缓存冲,写入到文件,如果下面已经没有写入的内容了,直接close也会写入
writer.close();
//关闭写入流,同时会把缓冲区内容写入文件,所以上面的注释掉
fop.close();
// 关闭输出流,释放系统资源
FileInputStream fip = new FileInputStream(f);
// 构建FileInputStream对象
InputStreamReader reader = new InputStreamReader(fip, "UTF-8");
// 构建InputStreamReader对象,编码与写入相同
StringBuffer sb = new StringBuffer();
while (reader.ready()) {
sb.append((char) reader.read());
// 转成char加到StringBuffer对象中
}
System.out.println(sb.toString());
reader.close();
// 关闭读取流
fip.close();
// 关闭输入流,释放系统资源
}
}
Scanner
Scanner是java5的新特征 可以通过Scanner类来获取输入的字符串或者数字 字符
下面是获取输入字符串的例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import java.io.*;
import java.util.Scanner;
public class Test {
public static void main(String []args) throws IOException {
Scanner s = new Scanner(System.in);
if (s.hasNext()) {
String r = s.next();
System.out.println(r);
}
Scanner s1 = new Scanner(System.in);
if (s1.hasNextLine()) {
String r = s1.nextLine();
System.out.println(r);
}
}
}
`
next和nextLine的区别
next
- 一定要读取到有效字符后才可以结束输入。
- 对输入有效字符之前遇到的空白,next()方法会自动将其去掉。
- 只有输入有效字符后才将其后面输入的空白作为分隔符或者结束符。
- next() 不能得到带有空格的字符串。
nextLine
- 以Enter为结束符,也就是说 nextLine()方法返回的是输入回车之前的所有字符。
- 可以获得空白。
异常
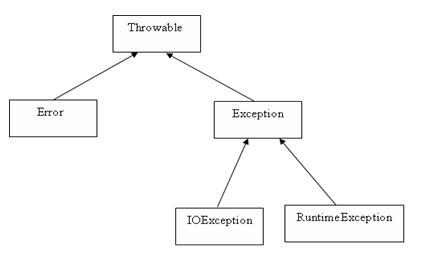
继承和接口
java的继承是单继承 就是说一个子类只可以有一个父类 同时java是支持多重继承的 就是说c可以继承b b继承a 这就是多重继承
但是java也是可以通过interface来实现多重继承的
例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28interface A{
public void eat();
}
interface B{
public void sleep();
}
class A_test implements A, B {
public void eat() {
System.out.println("this is eat func");
}
public void sleep() {
System.out.println("this is sleep func");
}
}
public class Test {
public static void main(String []args) {
A_test test_a = new A_test();
test_a.eat();
test_a.sleep();
}
}
值得一提的是 接口也可以初始化实例 并且这些接口初始化出来的实例也可以调用它们的方法 即使这些方法的定义在implements了它们的class中
构造函数
java的子类是不能继承夫类的构造函数的 但是当父类的构造函数含有参数时候 必须在子类的构造函数中使用super关键字调用父类构造函数 并且传入参数
但是当父类的构造函数没有参数 子类不是必须super调用父类构造函数的 因为系统会自动调用父类的无参构造函数
继承中的引用对象
可以使用
- 子类的构造函数构造父类的引用对象
- 不可以使用父类的构造函数构造子类的引用对象
如果使用的是子类的构造函数来构造父类的引用对象 那么这个对象调用的函数版本是子类中重写的版本
override和overload
重写
- 重写是在子类和父类之间的
- 重写的参数列表和返回类型必须相同
- 声明微final的方法不可以被重写
- 构造方法不可以被重写
- static方法不可以被重写 但是可以被重新声明
子类和父类都具有相同的static的的同名 同参数列表 同返回类型的函数 但是这不是重写 static函数不可以被重写 这是重新声明
static函数被重新声明的时候
无论父类的引用对象是被父类构造函数还是子类构造函数构造的 它调用的版本都是父类的static函数版本
子类的引用对象调用的版本是自己重新声明的static版本
例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import java.awt.*;
class Animal {
public void move() {
System.out.println("animal is move");
}
public static void testStatic() {
System.out.println("this is animal static func");
}
}
class Dog extends Animal {
public void move() {
System.out.println("Dog is move");
}
public static void testStatic() {
System.out.println("this is a Dog static funcss");
}
}
public class Test {
public static void main(String[] args) {
Animal a = new Animal();
Animal b = new Dog();
a.testStatic();
b.testStatic();
Dog c = new Dog();
c.testStatic();
}
}
输出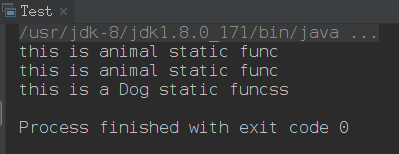
重载
- 在通一个class中
- 返回类型 函数名 参数列表相同
多态
多态是建立在上面的方法重写之上的 被重写的方法称为虚方法
多态的编译和运行
使用子类引用子类的对象
- 在编译的时候编译器会在子类中找到相应的方法 然后执行的时候JVM会调用子类的这个方法
使用父类引用子类的对象
- 在编译时 编译器会使用父类的虚方法进行验证 但是在运行时 JVM调用的是子类的对应的虚方法
java的所有方法都按照这种方式来实现 因此重写方法能在运行时调用 不敢编译的时候源代码中引用变量是什么数据类型
多态的实现方式
- 重写
- 接口
我一直以为重写是实现多态的唯一方式 但是java里面接口也是实现多态的一种方式 比如上面的多态内容中 我不是发现使用implements了接口的类构造函数类来创建一个interface引用对象 并且可以调用实现方法在这个class中的方法 所以这也是实现多态的一种方式
例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import java.awt.*;
interface A {
public void move();
}
class Dog implements A {
public void move() {
System.out.println("this is move func in Dog");
}
}
public class Test {
public static void main(String[] args) {
A testA = new Dog();
testA.move();
}
}
注意 interface没有构造函数 因为根本不能用以实例化一个对象
接口
interface特性
- 每个接口的方法都隐士指定为public abstract 其他修饰符都会报错
- 接口中可以有变量到 都会被隐士指定为public static final 使用private修饰编译会报错
- 接口的方法不能在接口中实现 只能由实现接口的类来实现
- 接口可以继承 这个跟类的继承相似 但是类只支持多重继承 不支持多继承 接口的继承支持多继承也支持多重继承
标记接口
最常用的继承接口是没有包含任何方法的接口和属性的 这个叫做标记接口 主要是表明它的类属于一个特定的类型
目的
- 建立一个公共的父接口 正如EventListener接口,这是由几十个其他接口扩展的Java API,你可以使用一个标记接口来建立一组接口的父接口。例如:当一个接口继承了EventListener接口,Java虚拟机(JVM)就知道该接口将要被用于一个事件的代理方案
- 向一个类添加数据类型 这种情况是标记接口最初的目的,实现标记接口的类不需要定义任何接口方法(因为标记接口根本就没有方法),但是该类通过多态性变成一个接口类型
包
同一个包内的类命名是不可以相同的 但是不同包内的命名是可以相同的
包例子:
结构如下
- animal
- Animal.java(Animal interface)
- MammalInt.java(MammalInt class implements Animal)
- Test.java(import animal.MammalInt)
Animal.java1
2
3
4
5package animal;
interface Animal {
public void eat();
}
MammalInt.jav1
2
3
4
5
6
7
8
9
10
11
12package animal;
public class MammalInt implements Animal {
public void eat() {
System.out.println("this is is animal eat func");
}
public static void main(String[] args) {
MammalInt testM = new MammalInt();
testM.eat();
}
}
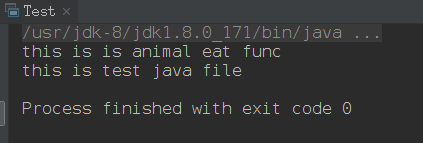
Test.java1
2
3
4
5
6
7
8
9
10
11import animal.MammalInt;
public class Test {
public static void main(String[] args) {
MammalInt testM = new MammalInt();
testM.eat();
System.out.println("this is test java file");
}
}
运行Test.java